Closures
正如那个人所说,对于每一个复杂的问题,都有一个简单的解决方案,这是错误的。
翁贝托·艾柯, 福柯的钟摆
感谢我们在上一章的辛勤劳动,我们有了一个具有函数功能的虚拟机。它缺少的是闭包特性。除了作为它们自己的动物品种的全局变量之外,函数无法引用在其自身主体之外声明的变量。
var x = "global"; fun outer() { var x = "outer"; fun inner() { print x; } inner(); } outer();
现在运行这个例子,它会打印出“global”。它应该打印“outer”。为了解决这个问题,我们需要在对变量进行决议时包括所有周围函数的整个词法作用域。
这个问题在clox中比在jlox中更难,因为我们的字节码VM将局部变量存储在栈上。我们使用栈是因为我声称局部变量具有栈语义——变量以与它们创建时相反的顺序被丢弃。但是对于闭包,这只在大部分情况下正确。
fun makeClosure() { var local = "local"; fun closure() { print local; } return closure; } var closure = makeClosure(); closure();
外部函数makeClosure()声明了一个变量local。它还创建了一个内部函数,closure()用于捕获该变量。然后makeClosure()返回对该函数的引用。由于闭包在保持局部变量的同时逃逸了,因此local必须比创建它的函数调用生命周期更长。
我们可以通过为所有局部变量动态分配内存来解决这个问题。这就是jlox所做的,将所有东西放在Java堆中浮动的Environment对象中。但我们不想在clox中这样做。因为使用栈非常快。大多数局部变量不会被闭包捕获,并且确实具有栈语义。为了被捕获的稀有的局部变量的利益,让所有这些都变慢是很糟糕的。
这需要我们使用比在Java解释器中使用的更复杂的方法。因为一些局部变量的生命周期和普通的局部变量很不同,我们将有两种实现策略。对于没有在闭包中使用的局部变量,我们将在栈上维护它们。当一个局部变量被闭包捕获时,我们将采用另一种解决方案,将他们提升到堆上,在那里它们可以根据需要维护自己的生命周期。
自从早期的Lisp时代以来,闭包就一直存在,当时内存字节和CPU周期比祖母绿更宝贵。在过去的几十年里,黑客设计了各种方法来编译闭包以优化运行时表示。有些效率更高,但需要更复杂的编译过程,我们没有办法将它们轻松地改装到clox中。
我在这里讲解的技术来自Lua VM的设计。它快速、节省内存,并且可以用相对较少的代码实现。更令人印象深刻的是,它天然地适合clox和Lua都使用的单遍编译器。不过,这有点复杂。可能需要一段时间才能让所有部分在你的脑海中合二为一。我们将一步一步构建它们,我将尝试分阶段介绍这些概念。
25 . 1闭包对象
我们的VM使用ObjFunction在运行时表示函数。这些对象是在编译期由前端创建的。在运行时,VM 所做的只是从一个常量表中加载函数对象并将其绑定到一个名称。在运行时没有“创建”函数的操作。很像字符串和数值字面量,它们是纯粹在编译时实例化的常量。
这是有道理的,因为构成函数的所有数据在编译时都是已知的:从函数体编译的字节码块,以及函数体中使用的常量。但是,一旦我们引入了闭包,这种表示就不再足够了。看一看:
fun makeClosure(value) { fun closure() { print value; } return closure; } var doughnut = makeClosure("doughnut"); var bagel = makeClosure("bagel"); doughnut(); bagel();
该makeClosure()函数定义并返回一个函数。我们调用两次这个函数并返回两个闭包。它们是由相同的嵌套函数声明创建的closure,但闭包了不同的值。当我们调用这两个闭包时,每个闭包都打印一个不同的字符串。这意味着我们需要针对闭包设计一些其它的运行时表示来捕获函数周围的局部变量,因为它们在函数声明执行时存在,而不仅仅是在编译时。
我们将努力捕获变量,但第一步是定义它的对象表示。我们现有的ObjFunction类型表示函数声明的“原始”编译时状态,因为从单个声明创建的所有闭包共享相同的代码和常量。在运行时,当我们执行一个函数声明时,我们将ObjFunction包装在一个新的ObjClosure结构中。后者具有对底层裸函数的引用以及函数闭包的变量的运行时状态。
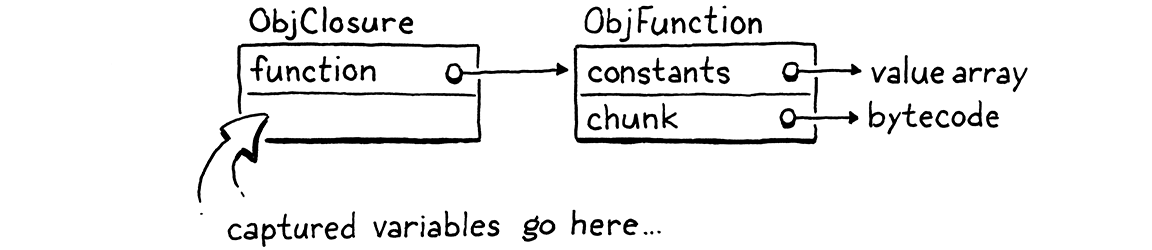
我们会将每个函数包装在ObjClosure中,即使该函数实际上并没有闭包并捕获任何周围的局部变量。这有点浪费,但它简化了VM,因为我们总是可以假设我们正在调用的函数是ObjClosure。新的结构体是这样开始的:
add after struct ObjString
typedef struct { Obj obj; ObjFunction* function; } ObjClosure;
现在,它只是指向一个ObjFunction并添加必要的对象头部内容。通过向clox添加新对象类型的惯常做法,我们声明了一个C函数来创建一个新的闭包。
} ObjClosure;
add after struct ObjClosure
ObjClosure* newClosure(ObjFunction* function);
ObjFunction* newFunction();
然后我们在这里实现它:
add after allocateObject()
ObjClosure* newClosure(ObjFunction* function) { ObjClosure* closure = ALLOCATE_OBJ(ObjClosure, OBJ_CLOSURE); closure->function = function; return closure; }
它需要一个指向它包装的ObjFunction的指针。它还将类型字段初始化为新类型。
typedef enum {
in enum ObjType
OBJ_CLOSURE,
OBJ_FUNCTION,
当一个闭包执行完毕时,我们释放它的内存。
switch (object->type) {
in freeObject()
case OBJ_CLOSURE: { FREE(ObjClosure, object); break; }
case OBJ_FUNCTION: {
我们只释放ObjClosure本身,而不释放ObjFunction。那是因为闭包不拥有这个函数。可能有多个闭包都引用同一个函数,并且没有一个声称对它有任何特殊的特权。在引用ObjFunction的所有对象都消失之前,我们无法释放ObjFunction——甚至包括常量表里包含这个ObjFunction的周围函数也无法被释放。跟踪听起来很棘手,而且确实如此!这就是为什么我们将很快编写一个垃圾收集器来为我们管理它。
我们还有用于检查值类型的一些常用的宏。
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
#define IS_CLOSURE(value) isObjType(value, OBJ_CLOSURE)
#define IS_FUNCTION(value) isObjType(value, OBJ_FUNCTION)
并对值进行强制类型转换:
#define IS_STRING(value) isObjType(value, OBJ_STRING)
#define AS_CLOSURE(value) ((ObjClosure*)AS_OBJ(value))
#define AS_FUNCTION(value) ((ObjFunction*)AS_OBJ(value))
闭包是一等公民对象,所以你可以打印它们。
switch (OBJ_TYPE(value)) {
in printObject()
case OBJ_CLOSURE: printFunction(AS_CLOSURE(value)->function); break;
case OBJ_FUNCTION:
闭包的打印与ObjFunction完全一样。从用户的角度来看,ObjFunction和ObjClosure的区别纯粹是隐藏的实现细节。有了这个,我们就有了一个可以工作但是为空的闭包表示。
25 . 1 . 1编译成闭包对象
我们有闭包对象,但我们的虚拟机从不创建它们。下一步是让编译器发出指令来告诉运行时何时创建一个新的ObjClosure来包装给定的ObjFunction。这发生在函数声明的末尾。
ObjFunction* function = endCompiler();
in function()
replace 1 line
emitBytes(OP_CLOSURE, makeConstant(OBJ_VAL(function)));
}
以前,函数声明的最后一条字节码是一条OP_CONSTANT指令,用于从周围函数的常量表中加载编译后的函数并将其压栈。现在我们有了新的指令。
OP_CALL,
in enum OpCode
OP_CLOSURE,
OP_RETURN,
就像OP_CONSTANT,它需要函数在常量表中的索引作为操作数。但是当我们进入运行时实现时,我们会做一些更有趣的事情。
首先,作为勤奋的VM黑客,让我们为指令提供反汇编支持。
case OP_CALL:
return byteInstruction("OP_CALL", chunk, offset);
in disassembleInstruction()
case OP_CLOSURE: { offset++; uint8_t constant = chunk->code[offset++]; printf("%-16s %4d ", "OP_CLOSURE", constant); printValue(chunk->constants.values[constant]); printf("\n"); return offset; }
case OP_RETURN:
这里发生的事情比我们通常在反汇编程序中所做的要多。在本章结束时,你会发现OP_CLOSURE是一条非常不寻常的指令。现在很简单——只是一个单字节操作数——但我们将为它添加其它东西。这里的代码预测了未来。
25 . 1 . 2解释执行函数声明
我们需要做的大部分工作都在运行时。自然,我们必须处理新指令。但我们还需要触及VM中与ObjFunction一起工作的每一段代码,并将其更改为使用ObjClosure——函数调用、调用帧等。不过,我们将从指令开始。
}
in run()
case OP_CLOSURE: { ObjFunction* function = AS_FUNCTION(READ_CONSTANT()); ObjClosure* closure = newClosure(function); push(OBJ_VAL(closure)); break; }
case OP_RETURN: {
和我们之前使用的OP_CONSTANT指令一样,首先我们从常量表中加载编译好的函数。现在的不同之处在于我们将该函数包装在一个新的ObjClosure中并将结果压栈。
一旦你有一个闭包,你最终会想要调用它。
switch (OBJ_TYPE(callee)) {
in callValue()
replace 2 lines
case OBJ_CLOSURE: return call(AS_CLOSURE(callee), argCount);
case OBJ_NATIVE: {
我们删除了调用类型为OBJ_FUNCTION的对象的代码。由于我们将所有函数包装在ObjClosure中,因此运行时将不再尝试调用裸的ObjFunction。这些对象只存在于常量表中,并在其他任何东西看到它们之前就被包装在闭包中了。
我们用非常相似的代码替换旧代码来调用闭包。唯一的区别是我们传递给call()方法的对象类型有所不同。该函数的真正变化已经结束。首先,我们更新它的签名。
function call()
replace 1 line
static bool call(ObjClosure* closure, int argCount) {
if (argCount != function->arity) {
然后,在主体中,我们需要修复引用该函数的所有内容,以处理我们引入了间接层的事实。我们从元数检查开始:
static bool call(ObjClosure* closure, int argCount) {
in call()
replace 3 lines
if (argCount != closure->function->arity) { runtimeError("Expected %d arguments but got %d.", closure->function->arity, argCount);
return false;
唯一的变化是我们打开闭包以访问底层函数。接下来的call()方法创建一个新的CallFrame。我们更改代码将闭包存储在CallFrame中,并从闭包的函数中获取字节码指针。
CallFrame* frame = &vm.frames[vm.frameCount++];
in call()
replace 2 lines
frame->closure = closure; frame->ip = closure->function->chunk.code;
frame->slots = vm.stackTop - argCount - 1;
同时需要更改CallFrame的声明。
typedef struct {
in struct CallFrame
replace 1 line
ObjClosure* closure;
uint8_t* ip;
上面的更改会触发其他一些级联更改。VM中每个访问CallFrame函数的地方都需要使用闭包。首先,更改从当前函数的常量表中读取常量的宏:
(uint16_t)((frame->ip[-2] << 8) | frame->ip[-1]))
in run()
replace 2 lines
#define READ_CONSTANT() \ (frame->closure->function->chunk.constants.values[READ_BYTE()])
#define READ_STRING() AS_STRING(READ_CONSTANT())
启用DEBUG_TRACE_EXECUTION时,它需要从闭包中获取块。
printf("\n");
in run()
replace 2 lines
disassembleInstruction(&frame->closure->function->chunk, (int)(frame->ip - frame->closure->function->chunk.code));
#endif
在报告运行时错误时:
CallFrame* frame = &vm.frames[i];
in runtimeError()
replace 1 line
ObjFunction* function = frame->closure->function;
size_t instruction = frame->ip - function->chunk.code - 1;
差不多好了。最后一部分代码块,用来设置第一个CallFrame以开始执行Lox脚本的顶层代码。
push(OBJ_VAL(function));
in interpret()
replace 1 line
ObjClosure* closure = newClosure(function); pop(); push(OBJ_VAL(closure)); call(closure, 0);
return run();
编译脚本时,编译器仍会返回一个原始的ObjFunction。这很好,但这意味着我们需要在这里将它包装在一个ObjClosure中,然后VM才能执行它。
我们又回到了正在工作的解释器身上。用户无法分辨出任何区别,但编译器现在在生成代码时,会告诉VM为每个函数声明创建一个闭包。每次VM执行函数声明时,它都会将ObjFunction包装在一个新的ObjClosure中。VM的其余部分现在处理那些浮动的ObjClosure。这就是那些无聊的东西。现在我们已经准备好让这些闭包真正做点什么了。
25 . 2Upvalues
我们现有的读取和写入局部变量的指令仅限于单个函数的栈窗口。来自周围函数的局部变量位于内部函数的窗口之外。我们需要一些新的指令。
最简单的方法可能是这样一条指令,这条指令接收栈的相对偏移量,通过这个相对偏移量可以访问当前函数窗口之前的位置。如果被闭包的变量总是在栈上,那将起作用。但正如我们之前看到的,这些变量的生命周期可能比声明它们的函数更长。这意味着它们不会总是在栈上。
那么,还有一个简单的方法是获取任何被闭包的局部变量并让它始终存在于堆上。当执行周围函数中的局部变量声明时,VM会为其动态分配内存。这样它就可以活到需要的时间。
如果clox没有使用单遍编译的实现方式,这将是一个很好的方法。但是我们选择了这种实现方式使事情变得更加困难了。看看这个例子:
fun outer() { var x = 1; // (1) x = 2; // (2) fun inner() { // (3) print x; } inner(); }
在这里,编译器编译位于(1)的x的声明并为位于(2)的赋值发出代码。在到达位于(3)的inner()的声明并发现x事实上已经被闭包之前,就完成了上一句话的操作。我们没有简单的方法可以返回并修复已经发出的代码来对x进行特殊地处理。相反,我们想要一个解决方案,允许将要被闭包的变量完全像普通局部变量一样存在于栈上,直到它被闭包为止。
幸运的是,感谢Lua开发团队,我们有了一个解决方案。我们使用他们称之为upvalue的中间层。upvalue是指函数中被闭包的局部变量。每个闭包都维护一个upvalue数组,数组中的每个upvalue对应了闭包所使用的外部函数的一个局部变量。
upvalue指向栈中它对应的捕获的变量所在的位置。当闭包需要访问一个被闭包的变量时,它会通过相应的upvalue来访问它。当一个函数声明第一次被执行并为这个函数创建一个闭包时,VM会创建一个upvalue数组并将它们和“捕获”的外部函数的局部变量连接起来。
例如,如果我们将这个程序扔给clox,
{
var a = 3;
fun f() {
print a;
}
}
编译器和运行时将共同在内存中构建一组对象,如下所示:
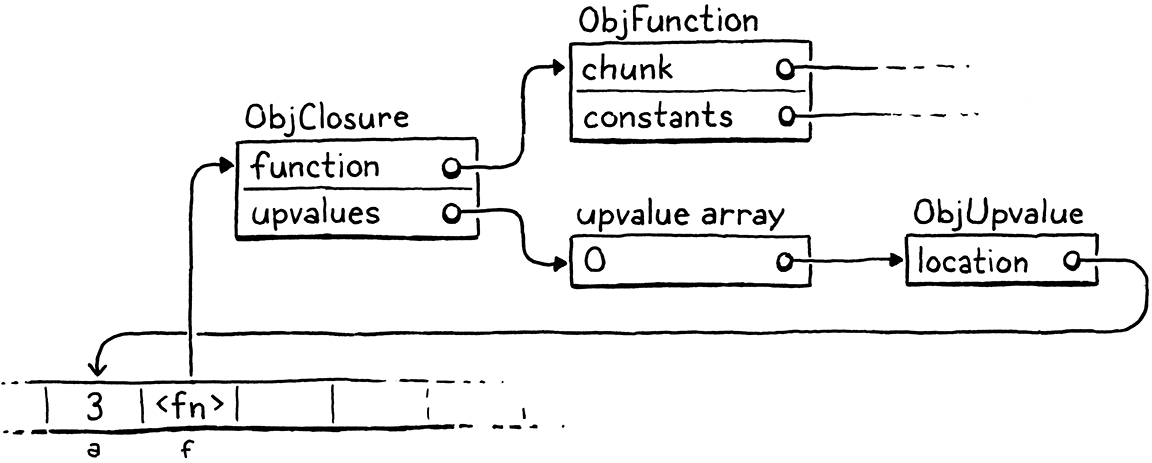
这可能看起来势不可挡,但不要害怕。我们会努力解决的。重要的部分是,upvalue作为中间层,即使在它移出栈后也能继续找到捕获的局部变量。但在我们开始之前,让我们专注于编译捕获的变量。
25 . 2 . 1编译upvalue
像往常一样,我们希望在编译期做尽可能多的工作,以保持执行的简单和快速。由于局部变量在Lox中的作用域是词法作用域,因此我们在编译期有足够的信息来确定函数访问哪些周围的局部变量以及在哪里声明了这些局部变量。反过来,这意味着我们知道闭包需要多少upvalue,它们捕获哪些变量,以及在声明函数的栈窗口中栈中的哪些地方包含这些变量。
目前,当编译器对一个标识符进行决议时,它会从当前函数的块作用域的最内层一直遍历到最外层。如果我们在该函数中找不到变量,我们假设该变量必须是全局变量。我们不考虑包围当前函数的外部函数的局部作用域——它们会被直接跳过。所以,第一个更改就是为那些外部函数的局部作用域插入变量的决议步骤。
if (arg != -1) {
getOp = OP_GET_LOCAL;
setOp = OP_SET_LOCAL;
in namedVariable()
} else if ((arg = resolveUpvalue(current, &name)) != -1) { getOp = OP_GET_UPVALUE; setOp = OP_SET_UPVALUE;
} else {
这个新的resolveUpvalue()函数查找在任何周围函数中声明的局部变量。如果找到一个,它会为该变量返回一个“upvalue index”。(我们稍后会讨论这意味着什么。)否则,它返回-1以指示未找到该变量。如果找到了,我们使用下面的两条新指令通过其upvalue读取或写入变量:
OP_SET_GLOBAL,
in enum OpCode
OP_GET_UPVALUE, OP_SET_UPVALUE,
OP_EQUAL,
我们正在实现这种自上而下的方式,所以我将很快向你展示它们在运行时是如何工作的。现在要关注的部分是编译器如何对标识符进行决议。
add after resolveLocal()
static int resolveUpvalue(Compiler* compiler, Token* name) { if (compiler->enclosing == NULL) return -1; int local = resolveLocal(compiler->enclosing, name); if (local != -1) { return addUpvalue(compiler, (uint8_t)local, true); } return -1; }
如果我们在当前函数作用域中对某个局部变量决议失败,就调用这个方法。因此我们知道该变量不在当前compiler中。回想一下,Compiler存储了一个指向包含周围函数的Compiler的指针,这些指针形成一条链接起来的链,一直链接到顶层代码的根Compiler。因此,如果包含外部函数的Compiler是NULL,我们就知道已经到达了最外层的函数,但却并没有找到局部变量。那么变量就是全局变量了,所以我们返回-1。
否则,我们尝试将标识符决议为外围compiler中的局部变量。换句话说,我们在当前函数之外寻找它。例如:
fun outer() { var x = 1; fun inner() { print x; // (1) } inner(); }
当我们在(1)处编译标识符表达式时,resolveUpvalue()会去查找在outer()中声明的局部变量。如果找到——就像在这个例子中一样——那么我们就成功地决议了这个变量。我们创建一个upvalue,以便内部函数可以通过它访问外部变量。upvalue在这里创建:
add after resolveLocal()
static int addUpvalue(Compiler* compiler, uint8_t index, bool isLocal) { int upvalueCount = compiler->function->upvalueCount; compiler->upvalues[upvalueCount].isLocal = isLocal; compiler->upvalues[upvalueCount].index = index; return compiler->function->upvalueCount++; }
compiler维护一个upvalue数组来跟踪它在每个函数体中决议的被闭包的标识符。还记得compiler的Local数组是如何镜像局部变量在运行时所在的栈索引的吗?这个新的upvalue数组的工作方式也是同样的。compiler数组中的索引与运行时upvalue将存在于ObjClosure中的索引一一对应。
这个函数向upvalue数组添加了一个新的upvalue。它还跟踪函数使用的upvalue数量。它将计数值直接存储在ObjFunction中,因为我们还需要在运行时使用计数值。
index字段跟踪被闭包的局部变量在栈中的索引。这样compiler就知道需要捕获外部函数中的哪个变量。不久之后,我们将回来讨论isLocal字段的用途。最后,addUpvalue()返回函数的upvalue列表中创建的upvalue的索引。该索引成为OP_GET_UPVALUE和OP_SET_UPVALUE指令的操作数。
这就是对upvalue进行决议的基本思想,但这个函数还没有完全成熟。闭包可以多次引用周围函数中的同一个变量。在这种情况下,我们不想浪费时间和内存为每个标识符表达式创建单独的upvalue。为了解决这个问题,在我们想要为某个被闭包的变量添加一个新的upvalue之前,我们首先检查函数是否已经有一个这个被闭包的变量所对应的upvalue。
int upvalueCount = compiler->function->upvalueCount;
in addUpvalue()
for (int i = 0; i < upvalueCount; i++) { Upvalue* upvalue = &compiler->upvalues[i]; if (upvalue->index == index && upvalue->isLocal == isLocal) { return i; } }
compiler->upvalues[upvalueCount].isLocal = isLocal;
如果我们在upvalue数组中找到一个upvalue,其栈索引与我们将要添加的upvalue匹配,我们只需返回该upvalue索引并重用它就可以了。否则,我们就添加新的upvalue。
这两个函数会访问和修改一堆新状态,所以让我们定义它。首先,我们将upvalue的计数值添加到 ObjFunction中。
int arity;
in struct ObjFunction
int upvalueCount;
Chunk chunk;
我们是认真的C程序员,所以我们在第一次分配ObjFunction时将计数值初始化为零。
function->arity = 0;
in newFunction()
function->upvalueCount = 0;
function->name = NULL;
在compiler中,我们为upvalue数组添加一个字段。
int localCount;
in struct Compiler
Upvalue upvalues[UINT8_COUNT];
int scopeDepth;
为简单起见,我给upvalue数组一个固定的大小。OP_GET_UPVALUE和OP_SET_UPVALUE指令使用单字节操作数对upvalue的索引进行编码,因此函数可以具有多少upvalue是有限制的——它可以闭包多少独一无二的变量。鉴于此,我们可以负担得起这么大的静态数组。我们还需要确保compiler不会超出该限制。
if (upvalue->index == index && upvalue->isLocal == isLocal) {
return i;
}
}
in addUpvalue()
if (upvalueCount == UINT8_COUNT) { error("Too many closure variables in function."); return 0; }
compiler->upvalues[upvalueCount].isLocal = isLocal;
最后,是Upvalue结构体类型本身。
add after struct Local
typedef struct { uint8_t index; bool isLocal; } Upvalue;
index字段存储upvalue正在捕获的局部变量在栈中的索引。isLocal字段你同样值得拥有,我们将在接下来讨论。
25 . 2 . 2将upvalue扁平化
在我之前展示的示例中,闭包正在访问外部函数中声明的变量。Lox还支持访问在任何外部作用域中声明的局部变量,如下所示:
fun outer() { var x = 1; fun middle() { fun inner() { print x; } } }
Here, we’re accessing x in inner(). That variable is defined not in
middle(), but all the way out in outer(). We need to handle cases like this
too. You might think that this isn’t much harder since the variable will
simply be somewhere farther down on the stack. But consider this devious example:
在这里,我们正在访问inner()中的x。x变量不是在middle()中定义的,而是在outer()中定义的。我们也需要处理这样的情况。你可能会认为这并不难,因为变量只是位于栈中更靠后的某个位置。但是考虑一下这个狡猾的例子:
fun outer() { var x = "value"; fun middle() { fun inner() { print x; } print "create inner closure"; return inner; } print "return from outer"; return middle; } var mid = outer(); var in = mid(); in();
当你运行它时,它应该打印:
return from outer create inner closure value
我知道,这很复杂。重要的部分是outer()——x在这里进行了声明——在执行inner()的声明之前outer()已经返回并从栈中弹出所有变量。因此,在我们为inner()创建闭包的时间点,x已经脱离了栈。
在这里,我为你追踪了执行流程:
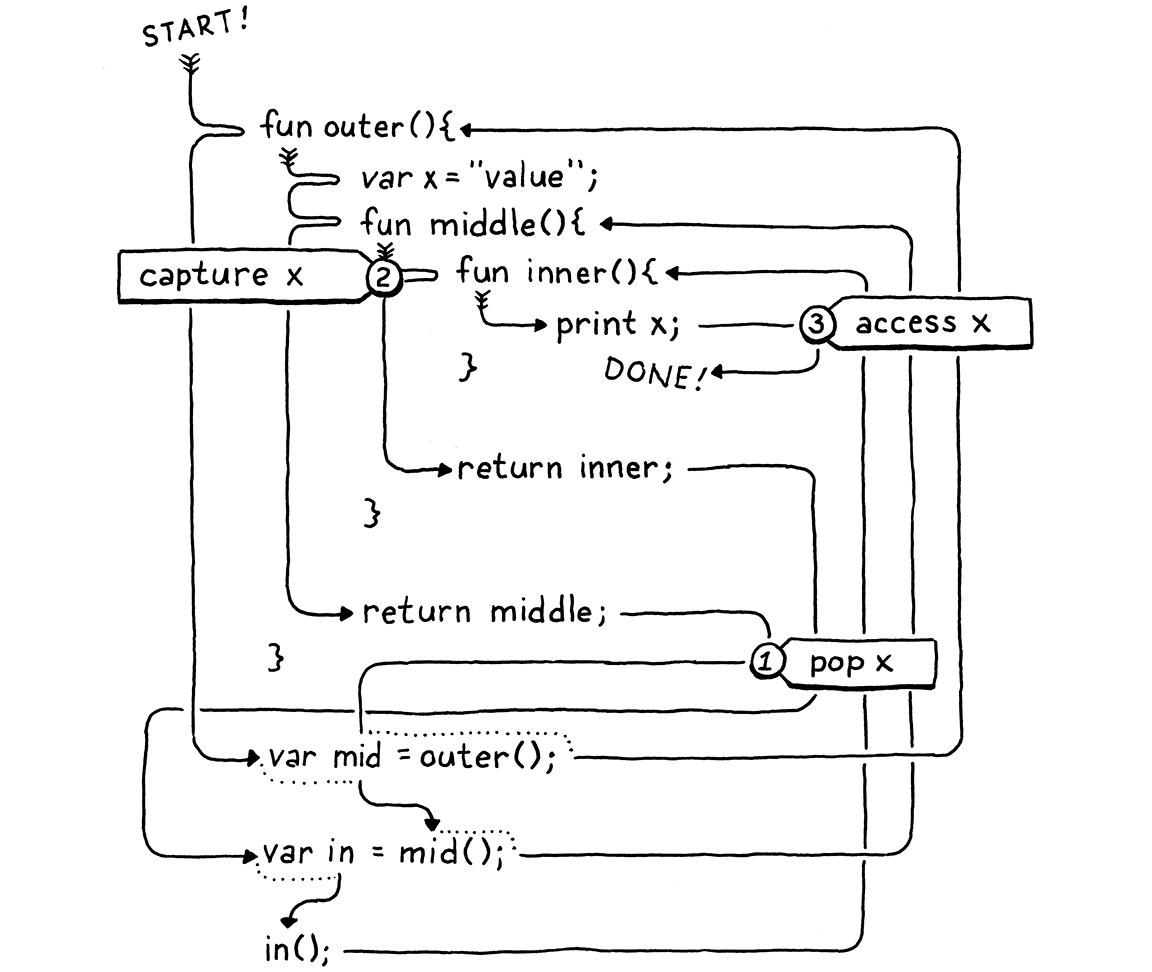
See how x is popped ① before it is captured ② and then later
accessed ③? We really have two problems:
看看x如何在被捕获之前②就被弹出①,然后再访问③?我们确实碰到了两个问题:
-
我们需要决议在紧邻的外部函数之外的外部函数中声明的局部变量。
-
我们需要能够捕获已经离开栈的变量。
幸运的是,我们正在向VM添加upvalue,upvalue是明确地设计用于跟踪已逃离栈的变量的。因此,在一个巧妙的自我引用中,我们可以使用upvalue来允许upvalue捕获在紧邻的外部函数之外声明的变量。
解决方案是允许闭包在直接紧邻的外部函数中捕获局部变量或现有的upvalue。如果一个深度嵌套的函数引用了一个声明在几层外部函数之外的局部变量,我们将通过让每个函数捕获一个upvalue以供下一个函数捕获,从而令其穿过所有中间函数。
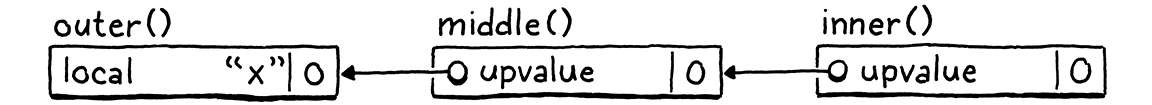
在上面的示例中,middle()捕获紧邻的外部函数outer()中的局部变量x,并将其存储在自己的upvalue中。即使middle()本身并没有引用x,它也会这样做。然后,当执行inner()的声明时,它的闭包从ObjClosure中获取middle()中x被捕获的上值。一个函数仅从紧邻的外部函数中捕获局部变量或upvalue,这样就保证了被捕获的局部变量或者upvalue仍然在内部函数的声明所执行的点的附近。
为了实现这一点,resolveUpvalue()必须是递归函数。
if (local != -1) {
return addUpvalue(compiler, (uint8_t)local, true);
}
in resolveUpvalue()
int upvalue = resolveUpvalue(compiler->enclosing, name); if (upvalue != -1) { return addUpvalue(compiler, (uint8_t)upvalue, false); }
return -1;
这只是另外三行代码,但我发现这个函数在第一次就完全编写正确是非常具有挑战性的。尽管事实上我并没有发明任何新东西,只是从Lua移植了这个概念。大多数递归函数要么在递归调用之前完成所有工作(前序遍历,或“在路上”),要么在递归调用之后完成所有工作(后序遍历,或“在备份的路上”)。这个函数两者兼而有之。递归调用就在中间。
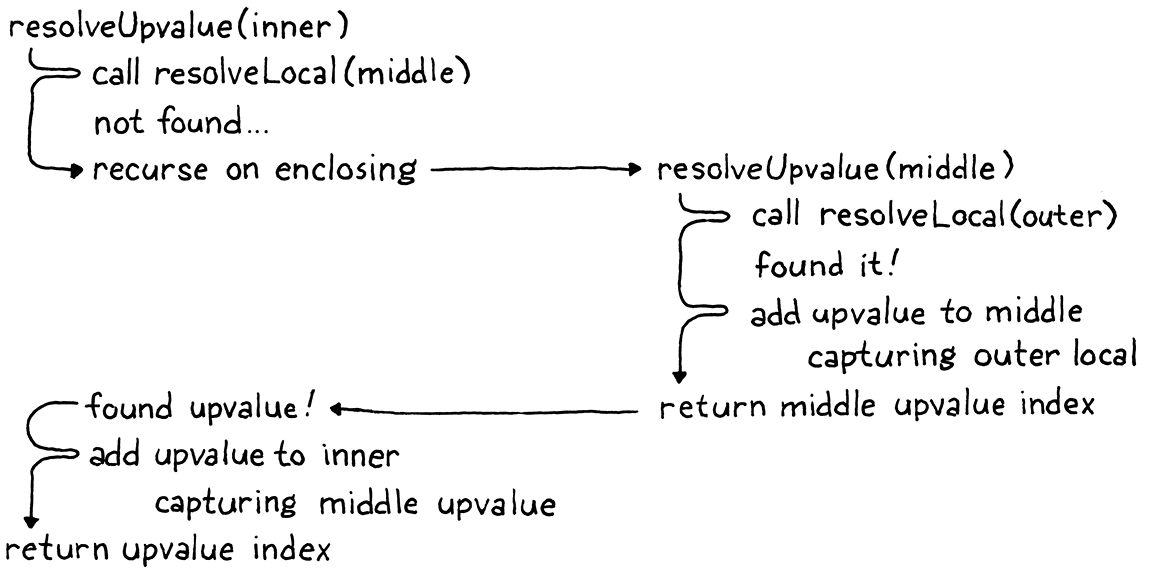
我们会慢慢走过。首先,我们在外部函数中寻找匹配的局部变量。如果我们找到一个,我们会捕获那个局部变量并将其返回。这是基本情况。
否则,我们会在紧邻的外部函数之外寻找一个局部变量。我们通过在紧邻的外部compiler而不是在当前compiler调用resolveUpvalue()来做到这一点。这一系列resolveUpvalue()调用沿着嵌套的compiler链运行,直到遇到一种基本情况——要么找到要捕获的实际局部变量,要么compiler链被用完。
当找到一个局部变量时,嵌套最深的resolveUpvalue()调用会捕获这个局部变量并返回upvalue的索引。这将返回到内部函数声明的下一次调用。调用从外部函数中捕获upvalue,依此类推。随着每个对resolveUpvalue()的嵌套调用返回,我们向下深入到最里面的函数声明,我们正在决议的标识符出现在该函数声明中。在此过程中的每一步,我们都会向中间函数添加一个upvalue,并将生成的upvalue索引向下传递给下一个调用。
It might help to walk through the original example when resolving x:
Note that the new call to addUpvalue() passes false for the isLocal
parameter. Now you see that that flag controls whether the closure captures a
local variable or an upvalue from the surrounding function.
By the time the compiler reaches the end of a function declaration, every variable reference has been resolved as either a local, an upvalue, or a global. Each upvalue may in turn capture a local variable from the surrounding function, or an upvalue in the case of transitive closures. We finally have enough data to emit bytecode which creates a closure at runtime that captures all of the correct variables.
emitBytes(OP_CLOSURE, makeConstant(OBJ_VAL(function)));
in function()
for (int i = 0; i < function->upvalueCount; i++) { emitByte(compiler.upvalues[i].isLocal ? 1 : 0); emitByte(compiler.upvalues[i].index); }
}
The OP_CLOSURE instruction is unique in that it has a variably sized encoding.
For each upvalue the closure captures, there are two single-byte operands. Each
pair of operands specifies what that upvalue captures. If the first byte is one,
it captures a local variable in the enclosing function. If zero, it captures one
of the function’s upvalues. The next byte is the local slot or upvalue index to
capture.
This odd encoding means we need some bespoke support in the disassembly code
for OP_CLOSURE.
printf("\n");
in disassembleInstruction()
ObjFunction* function = AS_FUNCTION(
chunk->constants.values[constant]);
for (int j = 0; j < function->upvalueCount; j++) {
int isLocal = chunk->code[offset++];
int index = chunk->code[offset++];
printf("%04d | %s %d\n",
offset - 2, isLocal ? "local" : "upvalue", index);
}
return offset;
For example, take this script:
fun outer() { var a = 1; var b = 2; fun middle() { var c = 3; var d = 4; fun inner() { print a + c + b + d; } } }
If we disassemble the instruction that creates the closure for inner(), it
prints this:
0004 9 OP_CLOSURE 2 <fn inner> 0006 | upvalue 0 0008 | local 1 0010 | upvalue 1 0012 | local 2
We have two other, simpler instructions to add disassembler support for.
case OP_SET_GLOBAL:
return constantInstruction("OP_SET_GLOBAL", chunk, offset);
in disassembleInstruction()
case OP_GET_UPVALUE: return byteInstruction("OP_GET_UPVALUE", chunk, offset); case OP_SET_UPVALUE: return byteInstruction("OP_SET_UPVALUE", chunk, offset);
case OP_EQUAL:
These both have a single-byte operand, so there’s nothing exciting going on. We
do need to add an include so the debug module can get to AS_FUNCTION().
#include "debug.h"
#include "object.h"
#include "value.h"
With that, our compiler is where we want it. For each function declaration, it
outputs an OP_CLOSURE instruction followed by a series of operand byte pairs
for each upvalue it needs to capture at runtime. It’s time to hop over to that
side of the VM and get things running.
25 . 3Upvalue Objects
Each OP_CLOSURE instruction is now followed by the series of bytes that
specify the upvalues the ObjClosure should own. Before we process those
operands, we need a runtime representation for upvalues.
add after struct ObjString
typedef struct ObjUpvalue { Obj obj; Value* location; } ObjUpvalue;
We know upvalues must manage closed-over variables that no longer live on the stack, which implies some amount of dynamic allocation. The easiest way to do that in our VM is by building on the object system we already have. That way, when we implement a garbage collector in the next chapter, the GC can manage memory for upvalues too.
Thus, our runtime upvalue structure is an ObjUpvalue with the typical Obj header
field. Following that is a location field that points to the closed-over
variable. Note that this is a pointer to a Value, not a Value itself. It’s a
reference to a variable, not a value. This is important because it means
that when we assign to the variable the upvalue captures, we’re assigning to the
actual variable, not a copy. For example:
fun outer() { var x = "before"; fun inner() { x = "assigned"; } inner(); print x; } outer();
This program should print “assigned” even though the closure assigns to x and
the surrounding function accesses it.
Because upvalues are objects, we’ve got all the usual object machinery, starting with a constructor-like function:
ObjString* copyString(const char* chars, int length);
add after copyString()
ObjUpvalue* newUpvalue(Value* slot);
void printObject(Value value);
It takes the address of the slot where the closed-over variable lives. Here is the implementation:
add after copyString()
ObjUpvalue* newUpvalue(Value* slot) { ObjUpvalue* upvalue = ALLOCATE_OBJ(ObjUpvalue, OBJ_UPVALUE); upvalue->location = slot; return upvalue; }
We simply initialize the object and store the pointer. That requires a new object type.
OBJ_STRING,
in enum ObjType
OBJ_UPVALUE
} ObjType;
And on the back side, a destructor-like function:
FREE(ObjString, object);
break;
}
in freeObject()
case OBJ_UPVALUE: FREE(ObjUpvalue, object); break;
}
Multiple closures can close over the same variable, so ObjUpvalue does not own the variable it references. Thus, the only thing to free is the ObjUpvalue itself.
And, finally, to print:
case OBJ_STRING:
printf("%s", AS_CSTRING(value));
break;
in printObject()
case OBJ_UPVALUE: printf("upvalue"); break;
}
Printing isn’t useful to end users. Upvalues are objects only so that we can take advantage of the VM’s memory management. They aren’t first-class values that a Lox user can directly access in a program. So this code will never actually execute . . . but it keeps the compiler from yelling at us about an unhandled switch case, so here we are.
25 . 3 . 1Upvalues in closures
When I first introduced upvalues, I said each closure has an array of them. We’ve finally worked our way back to implementing that.
ObjFunction* function;
in struct ObjClosure
ObjUpvalue** upvalues; int upvalueCount;
} ObjClosure;
Different closures may have different numbers of upvalues, so we need a dynamic array. The upvalues themselves are dynamically allocated too, so we end up with a double pointer—a pointer to a dynamically allocated array of pointers to upvalues. We also store the number of elements in the array.
When we create an ObjClosure, we allocate an upvalue array of the proper size, which we determined at compile time and stored in the ObjFunction.
ObjClosure* newClosure(ObjFunction* function) {
in newClosure()
ObjUpvalue** upvalues = ALLOCATE(ObjUpvalue*, function->upvalueCount); for (int i = 0; i < function->upvalueCount; i++) { upvalues[i] = NULL; }
ObjClosure* closure = ALLOCATE_OBJ(ObjClosure, OBJ_CLOSURE);
Before creating the closure object itself, we allocate the array of upvalues and
initialize them all to NULL. This weird ceremony around memory is a careful
dance to please the (forthcoming) garbage collection deities. It ensures the
memory manager never sees uninitialized memory.
Then we store the array in the new closure, as well as copy the count over from the ObjFunction.
closure->function = function;
in newClosure()
closure->upvalues = upvalues; closure->upvalueCount = function->upvalueCount;
return closure;
When we free an ObjClosure, we also free the upvalue array.
case OBJ_CLOSURE: {
in freeObject()
ObjClosure* closure = (ObjClosure*)object; FREE_ARRAY(ObjUpvalue*, closure->upvalues, closure->upvalueCount);
FREE(ObjClosure, object);
ObjClosure does not own the ObjUpvalue objects themselves, but it does own the array containing pointers to those upvalues.
We fill the upvalue array over in the interpreter when it creates a closure.
This is where we walk through all of the operands after OP_CLOSURE to see what
kind of upvalue each slot captures.
push(OBJ_VAL(closure));
in run()
for (int i = 0; i < closure->upvalueCount; i++) { uint8_t isLocal = READ_BYTE(); uint8_t index = READ_BYTE(); if (isLocal) { closure->upvalues[i] = captureUpvalue(frame->slots + index); } else { closure->upvalues[i] = frame->closure->upvalues[index]; } }
break;
This code is the magic moment when a closure comes to life. We iterate over each
upvalue the closure expects. For each one, we read a pair of operand bytes. If
the upvalue closes over a local variable in the enclosing function, we let
captureUpvalue() do the work.
Otherwise, we capture an upvalue from the surrounding function. An OP_CLOSURE
instruction is emitted at the end of a function declaration. At the moment that
we are executing that declaration, the current function is the surrounding
one. That means the current function’s closure is stored in the CallFrame at the
top of the callstack. So, to grab an upvalue from the enclosing function, we can
read it right from the frame local variable, which caches a reference to that
CallFrame.
Closing over a local variable is more interesting. Most of the work happens in a
separate function, but first we calculate the argument to pass to it. We need to
grab a pointer to the captured local’s slot in the surrounding function’s stack
window. That window begins at frame->slots, which points to slot zero. Adding
index offsets that to the local slot we want to capture. We pass that pointer
here:
add after callValue()
static ObjUpvalue* captureUpvalue(Value* local) { ObjUpvalue* createdUpvalue = newUpvalue(local); return createdUpvalue; }
This seems a little silly. All it does is create a new ObjUpvalue that captures the given stack slot and returns it. Did we need a separate function for this? Well, no, not yet. But you know we are going to end up sticking more code in here.
First, let’s wrap up what we’re working on. Back in the interpreter code for
handling OP_CLOSURE, we eventually finish iterating through the upvalue
array and initialize each one. When that completes, we have a new closure with
an array full of upvalues pointing to variables.
With that in hand, we can implement the instructions that work with those upvalues.
}
in run()
case OP_GET_UPVALUE: { uint8_t slot = READ_BYTE(); push(*frame->closure->upvalues[slot]->location); break; }
case OP_EQUAL: {
The operand is the index into the current function’s upvalue array. So we simply look up the corresponding upvalue and dereference its location pointer to read the value in that slot. Setting a variable is similar.
}
in run()
case OP_SET_UPVALUE: { uint8_t slot = READ_BYTE(); *frame->closure->upvalues[slot]->location = peek(0); break; }
case OP_EQUAL: {
We take the value on top of the stack and store it
into the slot pointed to by the chosen upvalue. Just as with the instructions
for local variables, it’s important that these instructions are fast. User
programs are constantly reading and writing variables, so if that’s slow,
everything is slow. And, as usual, the way we make them fast is by keeping them
simple. These two new instructions are pretty good: no control flow, no complex
arithmetic, just a couple of pointer indirections and a push().
This is a milestone. As long as all of the variables remain on the stack, we have working closures. Try this:
fun outer() { var x = "outside"; fun inner() { print x; } inner(); } outer();
Run this, and it correctly prints “outside”.
25 . 4Closed Upvalues
Of course, a key feature of closures is that they hold on to the variable as long as needed, even after the function that declares the variable has returned. Here’s another example that should work:
fun outer() { var x = "outside"; fun inner() { print x; } return inner; } var closure = outer(); closure();
But if you run it right now . . . who knows what it does? At runtime, it will end up reading from a stack slot that no longer contains the closed-over variable. Like I’ve mentioned a few times, the crux of the issue is that variables in closures don’t have stack semantics. That means we’ve got to hoist them off the stack when the function where they were declared returns. This final section of the chapter does that.
25 . 4 . 1Values and variables
Before we get to writing code, I want to dig into an important semantic point. Does a closure close over a value or a variable? This isn’t purely an academic question. I’m not just splitting hairs. Consider:
var globalSet; var globalGet; fun main() { var a = "initial"; fun set() { a = "updated"; } fun get() { print a; } globalSet = set; globalGet = get; } main(); globalSet(); globalGet();
The outer main() function creates two closures and stores them in global variables so that they outlive the execution of
main() itself. Both of those closures capture the same variable. The first
closure assigns a new value to it and the second closure reads the variable.
What does the call to globalGet() print? If closures capture values then
each closure gets its own copy of a with the value that a had at the point
in time that the closure’s function declaration executed. The call to
globalSet() will modify set()’s copy of a, but get()’s copy will be
unaffected. Thus, the call to globalGet() will print “initial”.
If closures close over variables, then get() and set() will both capture—reference—the same mutable variable. When set() changes a, it changes
the same a that get() reads from. There is only one a. That, in turn,
implies the call to globalGet() will print “updated”.
Which is it? The answer for Lox and most other languages I know with closures is the latter. Closures capture variables. You can think of them as capturing the place the value lives. This is important to keep in mind as we deal with closed-over variables that are no longer on the stack. When a variable moves to the heap, we need to ensure that all closures capturing that variable retain a reference to its one new location. That way, when the variable is mutated, all closures see the change.
25 . 4 . 2Closing upvalues
We know that local variables always start out on the stack. This is faster, and lets our single-pass compiler emit code before it discovers the variable has been captured. We also know that closed-over variables need to move to the heap if the closure outlives the function where the captured variable is declared.
Following Lua, we’ll use open upvalue to refer to an upvalue that points to a local variable still on the stack. When a variable moves to the heap, we are closing the upvalue and the result is, naturally, a closed upvalue. The two questions we need to answer are:
-
Where on the heap does the closed-over variable go?
-
When do we close the upvalue?
The answer to the first question is easy. We already have a convenient object on the heap that represents a reference to a variable—ObjUpvalue itself. The closed-over variable will move into a new field right inside the ObjUpvalue struct. That way we don’t need to do any additional heap allocation to close an upvalue.
The second question is straightforward too. As long as the variable is on the stack, there may be code that refers to it there, and that code must work correctly. So the logical time to hoist the variable to the heap is as late as possible. If we move the local variable right when it goes out of scope, we are certain that no code after that point will try to access it from the stack. After the variable is out of scope, the compiler will have reported an error if any code tried to use it.
The compiler already emits an OP_POP instruction when a local variable goes
out of scope. If a variable is captured by a closure, we will instead emit a
different instruction to hoist that variable out of the stack and into its
corresponding upvalue. To do that, the compiler needs to know which locals are closed over.
The compiler already maintains an array of Upvalue structs for each local variable in the function to track exactly that state. That array is good for answering “Which variables does this closure use?” But it’s poorly suited for answering, “Does any function capture this local variable?” In particular, once the Compiler for some closure has finished, the Compiler for the enclosing function whose variable has been captured no longer has access to any of the upvalue state.
In other words, the compiler maintains pointers from upvalues to the locals they capture, but not in the other direction. So we first need to add some extra tracking inside the existing Local struct so that we can tell if a given local is captured by a closure.
int depth;
in struct Local
bool isCaptured;
} Local;
This field is true if the local is captured by any later nested function
declaration. Initially, all locals are not captured.
local->depth = -1;
in addLocal()
local->isCaptured = false;
}
Likewise, the special “slot zero local” that the compiler implicitly declares is not captured.
local->depth = 0;
in initCompiler()
local->isCaptured = false;
local->name.start = "";
When resolving an identifier, if we end up creating an upvalue for a local variable, we mark it as captured.
if (local != -1) {
in resolveUpvalue()
compiler->enclosing->locals[local].isCaptured = true;
return addUpvalue(compiler, (uint8_t)local, true);
Now, at the end of a block scope when the compiler emits code to free the stack slots for the locals, we can tell which ones need to get hoisted onto the heap. We’ll use a new instruction for that.
while (current->localCount > 0 &&
current->locals[current->localCount - 1].depth >
current->scopeDepth) {
in endScope()
replace 1 line
if (current->locals[current->localCount - 1].isCaptured) { emitByte(OP_CLOSE_UPVALUE); } else { emitByte(OP_POP); }
current->localCount--; }
The instruction requires no operand. We know that the variable will always be right on top of the stack at the point that this instruction executes. We declare the instruction.
OP_CLOSURE,
in enum OpCode
OP_CLOSE_UPVALUE,
OP_RETURN,
And add trivial disassembler support for it:
}
in disassembleInstruction()
case OP_CLOSE_UPVALUE: return simpleInstruction("OP_CLOSE_UPVALUE", offset);
case OP_RETURN:
Excellent. Now the generated bytecode tells the runtime exactly when each captured local variable must move to the heap. Better, it does so only for the locals that are used by a closure and need this special treatment. This aligns with our general performance goal that we want users to pay only for functionality that they use. Variables that aren’t used by closures live and die entirely on the stack just as they did before.
25 . 4 . 3Tracking open upvalues
Let’s move over to the runtime side. Before we can interpret OP_CLOSE_UPVALUE
instructions, we have an issue to resolve. Earlier, when I talked about whether
closures capture variables or values, I said it was important that if multiple
closures access the same variable that they end up with a reference to the
exact same storage location in memory. That way if one closure writes to the
variable, the other closure sees the change.
Right now, if two closures capture the same local variable, the VM creates a separate Upvalue for each one. The necessary sharing is missing. When we move the variable off the stack, if we move it into only one of the upvalues, the other upvalue will have an orphaned value.
To fix that, whenever the VM needs an upvalue that captures a particular local variable slot, we will first search for an existing upvalue pointing to that slot. If found, we reuse that. The challenge is that all of the previously created upvalues are squirreled away inside the upvalue arrays of the various closures. Those closures could be anywhere in the VM’s memory.
The first step is to give the VM its own list of all open upvalues that point to variables still on the stack. Searching a list each time the VM needs an upvalue sounds like it might be slow, but in practice, it’s not bad. The number of variables on the stack that actually get closed over tends to be small. And function declarations that create closures are rarely on performance critical execution paths in the user’s program.
Even better, we can order the list of open upvalues by the stack slot index they point to. The common case is that a slot has not already been captured—sharing variables between closures is uncommon—and closures tend to capture locals near the top of the stack. If we store the open upvalue array in stack slot order, as soon as we step past the slot where the local we’re capturing lives, we know it won’t be found. When that local is near the top of the stack, we can exit the loop pretty early.
Maintaining a sorted list requires inserting elements in the middle efficiently. That suggests using a linked list instead of a dynamic array. Since we defined the ObjUpvalue struct ourselves, the easiest implementation is an intrusive list that puts the next pointer right inside the ObjUpvalue struct itself.
Value* location;
in struct ObjUpvalue
struct ObjUpvalue* next;
} ObjUpvalue;
When we allocate an upvalue, it is not attached to any list yet so the link is
NULL.
upvalue->location = slot;
in newUpvalue()
upvalue->next = NULL;
return upvalue;
The VM owns the list, so the head pointer goes right inside the main VM struct.
Table strings;
in struct VM
ObjUpvalue* openUpvalues;
Obj* objects;
The list starts out empty.
vm.frameCount = 0;
in resetStack()
vm.openUpvalues = NULL;
}
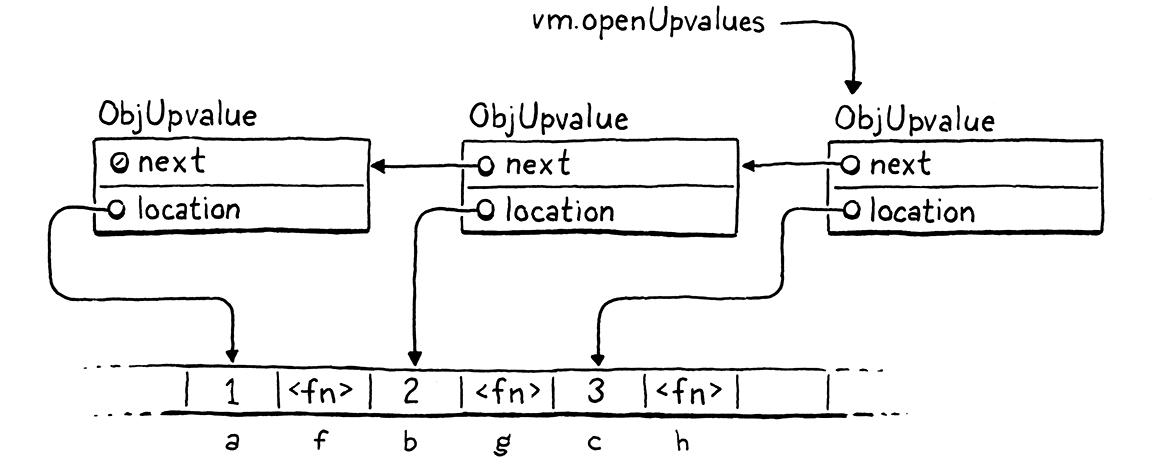
Starting with the first upvalue pointed to by the VM, each open upvalue points to the next open upvalue that references a local variable farther down the stack. This script, for example,
{
var a = 1;
fun f() {
print a;
}
var b = 2;
fun g() {
print b;
}
var c = 3;
fun h() {
print c;
}
}
should produce a series of linked upvalues like so:
Whenever we close over a local variable, before creating a new upvalue, we look for an existing one in the list.
static ObjUpvalue* captureUpvalue(Value* local) {
in captureUpvalue()
ObjUpvalue* prevUpvalue = NULL; ObjUpvalue* upvalue = vm.openUpvalues; while (upvalue != NULL && upvalue->location > local) { prevUpvalue = upvalue; upvalue = upvalue->next; } if (upvalue != NULL && upvalue->location == local) { return upvalue; }
ObjUpvalue* createdUpvalue = newUpvalue(local);
We start at the head of the list, which is the upvalue
closest to the top of the stack. We walk through the list, using a little
pointer comparison to iterate past every upvalue pointing to slots above the one
we’re looking for. While we do that, we keep track of the preceding upvalue on
the list. We’ll need to update that node’s next pointer if we end up inserting
a node after it.
There are three reasons we can exit the loop:
-
The local slot we stopped at is the slot we’re looking for. We found an existing upvalue capturing the variable, so we reuse that upvalue.
-
We ran out of upvalues to search. When
upvalueisNULL, it means every open upvalue in the list points to locals above the slot we’re looking for, or (more likely) the upvalue list is empty. Either way, we didn’t find an upvalue for our slot. -
We found an upvalue whose local slot is below the one we’re looking for. Since the list is sorted, that means we’ve gone past the slot we are closing over, and thus there must not be an existing upvalue for it.
In the first case, we’re done and we’ve returned. Otherwise, we create a new upvalue for our local slot and insert it into the list at the right location.
ObjUpvalue* createdUpvalue = newUpvalue(local);
in captureUpvalue()
createdUpvalue->next = upvalue; if (prevUpvalue == NULL) { vm.openUpvalues = createdUpvalue; } else { prevUpvalue->next = createdUpvalue; }
return createdUpvalue;
The current incarnation of this function already creates the upvalue, so we only
need to add code to insert the upvalue into the list. We exited the list
traversal by either going past the end of the list, or by stopping on the first
upvalue whose stack slot is below the one we’re looking for. In either case,
that means we need to insert the new upvalue before the object pointed at by
upvalue (which may be NULL if we hit the end of the list).
As you may have learned in Data Structures 101, to insert a node into a linked
list, you set the next pointer of the previous node to point to your new one.
We have been conveniently keeping track of that preceding node as we walked the
list. We also need to handle the special case where
we are inserting a new upvalue at the head of the list, in which case the “next”
pointer is the VM’s head pointer.
With this updated function, the VM now ensures that there is only ever a single ObjUpvalue for any given local slot. If two closures capture the same variable, they will get the same upvalue. We’re ready to move those upvalues off the stack now.
25 . 4 . 4Closing upvalues at runtime
The compiler helpfully emits an OP_CLOSE_UPVALUE instruction to tell the VM
exactly when a local variable should be hoisted onto the heap. Executing that
instruction is the interpreter’s responsibility.
}
in run()
case OP_CLOSE_UPVALUE: closeUpvalues(vm.stackTop - 1); pop(); break;
case OP_RETURN: {
When we reach the instruction, the variable we are hoisting is right on top of
the stack. We call a helper function, passing the address of that stack slot.
That function is responsible for closing the upvalue and moving the local from
the stack to the heap. After that, the VM is free to discard the stack slot,
which it does by calling pop().
The fun stuff happens here:
add after captureUpvalue()
static void closeUpvalues(Value* last) { while (vm.openUpvalues != NULL && vm.openUpvalues->location >= last) { ObjUpvalue* upvalue = vm.openUpvalues; upvalue->closed = *upvalue->location; upvalue->location = &upvalue->closed; vm.openUpvalues = upvalue->next; } }
This function takes a pointer to a stack slot. It closes every open upvalue it can find that points to that slot or any slot above it on the stack. Right now, we pass a pointer only to the top slot on the stack, so the “or above it” part doesn’t come into play, but it will soon.
To do this, we walk the VM’s list of open upvalues, again from top to bottom. If an upvalue’s location points into the range of slots we’re closing, we close the upvalue. Otherwise, once we reach an upvalue outside of the range, we know the rest will be too, so we stop iterating.
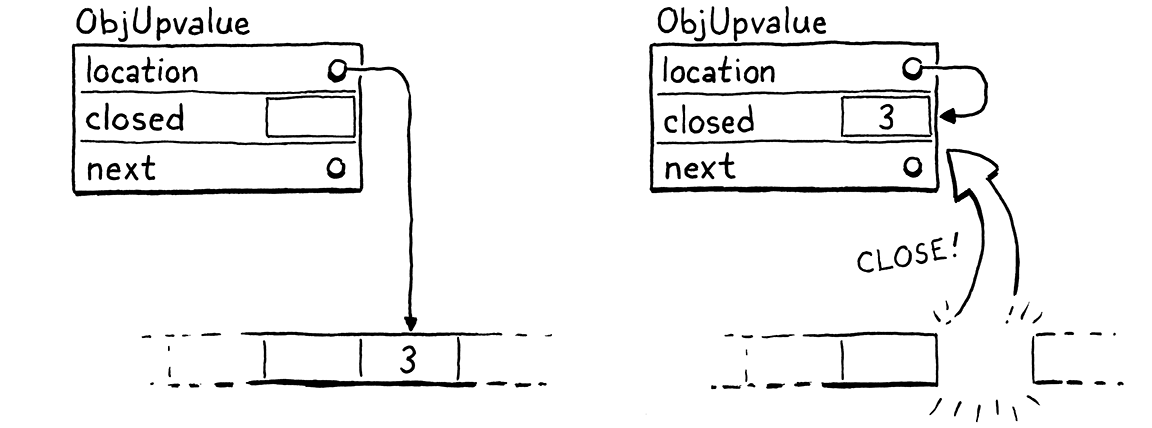
The way an upvalue gets closed is pretty cool. First,
we copy the variable’s value into the closed field in the ObjUpvalue. That’s
where closed-over variables live on the heap. The OP_GET_UPVALUE and
OP_SET_UPVALUE instructions need to look for the variable there after it’s
been moved. We could add some conditional logic in the interpreter code for
those instructions to check some flag for whether the upvalue is open or closed.
But there is already a level of indirection in play—those instructions
dereference the location pointer to get to the variable’s value. When the
variable moves from the stack to the closed field, we simply update that
location to the address of the ObjUpvalue’s own closed field.
We don’t need to change how OP_GET_UPVALUE and OP_SET_UPVALUE are
interpreted at all. That keeps them simple, which in turn keeps them fast. We do
need to add the new field to ObjUpvalue, though.
Value* location;
in struct ObjUpvalue
Value closed;
struct ObjUpvalue* next;
And we should zero it out when we create an ObjUpvalue so there’s no uninitialized memory floating around.
ObjUpvalue* upvalue = ALLOCATE_OBJ(ObjUpvalue, OBJ_UPVALUE);
in newUpvalue()
upvalue->closed = NIL_VAL;
upvalue->location = slot;
Whenever the compiler reaches the end of a block, it discards all local
variables in that block and emits an OP_CLOSE_UPVALUE for each local variable
that was closed over. The compiler does not emit any
instructions at the end of the outermost block scope that defines a function
body. That scope contains the function’s parameters and any locals declared
immediately inside the function. Those need to get closed too.
This is the reason closeUpvalues() accepts a pointer to a stack slot. When a
function returns, we call that same helper and pass in the first stack slot
owned by the function.
Value result = pop();
in run()
closeUpvalues(frame->slots);
vm.frameCount--;
By passing the first slot in the function’s stack window, we close every remaining open upvalue owned by the returning function. And with that, we now have a fully functioning closure implementation. Closed-over variables live as long as they are needed by the functions that capture them.
This was a lot of work! In jlox, closures fell out naturally from our environment representation. In clox, we had to add a lot of code—new bytecode instructions, more data structures in the compiler, and new runtime objects. The VM very much treats variables in closures as different from other variables.
There is a rationale for that. In terms of implementation complexity, jlox gave us closures “for free”. But in terms of performance, jlox’s closures are anything but. By allocating all environments on the heap, jlox pays a significant performance price for all local variables, even the majority which are never captured by closures.
With clox, we have a more complex system, but that allows us to tailor the implementation to fit the two use patterns we observe for local variables. For most variables which do have stack semantics, we allocate them entirely on the stack which is simple and fast. Then, for the few local variables where that doesn’t work, we have a second slower path we can opt in to as needed.
Fortunately, users don’t perceive the complexity. From their perspective, local variables in Lox are simple and uniform. The language itself is as simple as jlox’s implementation. But under the hood, clox is watching what the user does and optimizing for their specific uses. As your language implementations grow in sophistication, you’ll find yourself doing this more. A large fraction of “optimization” is about adding special case code that detects certain uses and provides a custom-built, faster path for code that fits that pattern.
We have lexical scoping fully working in clox now, which is a major milestone. And, now that we have functions and variables with complex lifetimes, we also have a lot of objects floating around in clox’s heap, with a web of pointers stringing them together. The next step is figuring out how to manage that memory so that we can free some of those objects when they’re no longer needed.
Challenges
-
Wrapping every ObjFunction in an ObjClosure introduces a level of indirection that has a performance cost. That cost isn’t necessary for functions that do not close over any variables, but it does let the runtime treat all calls uniformly.
Change clox to only wrap functions in ObjClosures that need upvalues. How does the code complexity and performance compare to always wrapping functions? Take care to benchmark programs that do and do not use closures. How should you weight the importance of each benchmark? If one gets slower and one faster, how do you decide what trade-off to make to choose an implementation strategy?
-
Read the design note below. I’ll wait. Now, how do you think Lox should behave? Change the implementation to create a new variable for each loop iteration.
-
A famous koan teaches us that “objects are a poor man’s closure” (and vice versa). Our VM doesn’t support objects yet, but now that we have closures we can approximate them. Using closures, write a Lox program that models two-dimensional vector “objects”. It should:
-
Define a “constructor” function to create a new vector with the given x and y coordinates.
-
Provide “methods” to access the x and y coordinates of values returned from that constructor.
-
Define an addition “method” that adds two vectors and produces a third.
-
Design Note: Closing Over the Loop Variable
Closures capture variables. When two closures capture the same variable, they share a reference to the same underlying storage location. This fact is visible when new values are assigned to the variable. Obviously, if two closures capture different variables, there is no sharing.
var globalOne; var globalTwo; fun main() { { var a = "one"; fun one() { print a; } globalOne = one; } { var a = "two"; fun two() { print a; } globalTwo = two; } } main(); globalOne(); globalTwo();
This prints “one” then “two”. In this example, it’s pretty clear that the two
a variables are different. But it’s not always so obvious. Consider:
var globalOne; var globalTwo; fun main() { for (var a = 1; a <= 2; a = a + 1) { fun closure() { print a; } if (globalOne == nil) { globalOne = closure; } else { globalTwo = closure; } } } main(); globalOne(); globalTwo();
The code is convoluted because Lox has no collection types. The important part
is that the main() function does two iterations of a for loop. Each time
through the loop, it creates a closure that captures the loop variable. It
stores the first closure in globalOne and the second in globalTwo.
There are definitely two different closures. Do they close over two different
variables? Is there only one a for the entire duration of the loop, or does
each iteration get its own distinct a variable?
The script here is strange and contrived, but this does show up in real code in languages that aren’t as minimal as clox. Here’s a JavaScript example:
var closures = []; for (var i = 1; i <= 2; i++) { closures.push(function () { console.log(i); }); } closures[0](); closures[1]();
Does this print “1” then “2”, or does it print “3”
twice? You may be surprised to hear that it prints “3” twice. In this JavaScript
program, there is only a single i variable whose lifetime includes all
iterations of the loop, including the final exit.
If you’re familiar with JavaScript, you probably know that variables declared
using var are implicitly hoisted to the surrounding function or top-level
scope. It’s as if you really wrote this:
var closures = []; var i; for (i = 1; i <= 2; i++) { closures.push(function () { console.log(i); }); } closures[0](); closures[1]();
At that point, it’s clearer that there is only a single i. Now consider if
you change the program to use the newer let keyword:
var closures = []; for (let i = 1; i <= 2; i++) { closures.push(function () { console.log(i); }); } closures[0](); closures[1]();
Does this new program behave the same? Nope. In this case, it prints “1” then
“2”. Each closure gets its own i. That’s sort of strange when you think about
it. The increment clause is i++. That looks very much like it is assigning to
and mutating an existing variable, not creating a new one.
Let’s try some other languages. Here’s Python:
closures = [] for i in range(1, 3): closures.append(lambda: print(i)) closures[0]() closures[1]()
Python doesn’t really have block scope. Variables are implicitly declared and
are automatically scoped to the surrounding function. Kind of like hoisting in
JS, now that I think about it. So both closures capture the same variable.
Unlike C, though, we don’t exit the loop by incrementing i past the last
value, so this prints “2” twice.
What about Ruby? Ruby has two typical ways to iterate numerically. Here’s the classic imperative style:
closures = [] for i in 1..2 do closures << lambda { puts i } end closures[0].call closures[1].call
This, like Python, prints “2” twice. But the more idiomatic Ruby style is using
a higher-order each() method on range objects:
closures = [] (1..2).each do |i| closures << lambda { puts i } end closures[0].call closures[1].call
If you’re not familiar with Ruby, the do |i| ... end part is basically a
closure that gets created and passed to the each() method. The |i| is the
parameter signature for the closure. The each() method invokes that closure
twice, passing in 1 for i the first time and 2 the second time.
In this case, the “loop variable” is really a function parameter. And, since each iteration of the loop is a separate invocation of the function, those are definitely separate variables for each call. So this prints “1” then “2”.
If a language has a higher-level iterator-based looping structure like foreach
in C#, Java’s “enhanced for”, for-of in JavaScript, for-in in Dart, etc.,
then I think it’s natural to the reader to have each iteration create a new
variable. The code looks like a new variable because the loop header looks
like a variable declaration. And there’s no increment expression that looks like
it’s mutating that variable to advance to the next step.
If you dig around StackOverflow and other places, you find evidence that this is
what users expect, because they are very surprised when they don’t get it. In
particular, C# originally did not create a new loop variable for each
iteration of a foreach loop. This was such a frequent source of user confusion
that they took the very rare step of shipping a breaking change to the language.
In C# 5, each iteration creates a fresh variable.
Old C-style for loops are harder. The increment clause really does look like
mutation. That implies there is a single variable that’s getting updated each
step. But it’s almost never useful for each iteration to share a loop
variable. The only time you can even detect this is when closures capture it.
And it’s rarely helpful to have a closure that references a variable whose value
is whatever value caused you to exit the loop.
The pragmatically useful answer is probably to do what JavaScript does with
let in for loops. Make it look like mutation but actually create a new
variable each time, because that’s what users want. It is kind of weird when you
think about it, though.