Representing Code
To dwellers in a wood, almost every species of tree has its voice as well as its feature. Thomas Hardy, Under the Greenwood Tree
在上一章中,我们以字符串形式接收原始源代码,并将其转换为一个稍高级别的表示:一系列词法标记。我们在下一章中要编写的语法分析器,会将这些词法标记再次转换为更丰富、更复杂的表示形式。
在我们能够输出这种表示形式之前,我们需要先对其进行定义。这就是本章的主题。在这一过程中,我们将围绕形式化文法进行一些理论讲解,感受函数式编程和面向对象编程的区别,会介绍几种设计模式,并进行一些元编程。
在做这些事情之前,我们先关注一下主要目标——代码的表示形式。它应该易于语法分析器生成,也易于解释器使用。如果你还没有编写过语法分析器或解释器,那么这样的需求描述并不能很好地说明问题。也许你的直觉可以帮助你。当你扮演一个人类解释器的角色时,你的大脑在做什么?你如何在心里计算这样的算术表达式:
1 + 2 * 3 - 4
因为你已经理解了运算的顺序——以前的“Please Excuse My Dear Aunt Sally”之类,你知道乘法在加减操作之前执行。有一种方法可以将这种优先级进行可视化,那就是使用树。叶子节点是数值,内部节点是运算符,它们的每个操作数都对应一个分支。
要想计算一个算术节点,你需要知道它的子树的数值,所以你必须先计算子树的结果。这意味着要从叶节点一直计算到根节点——后序遍历:
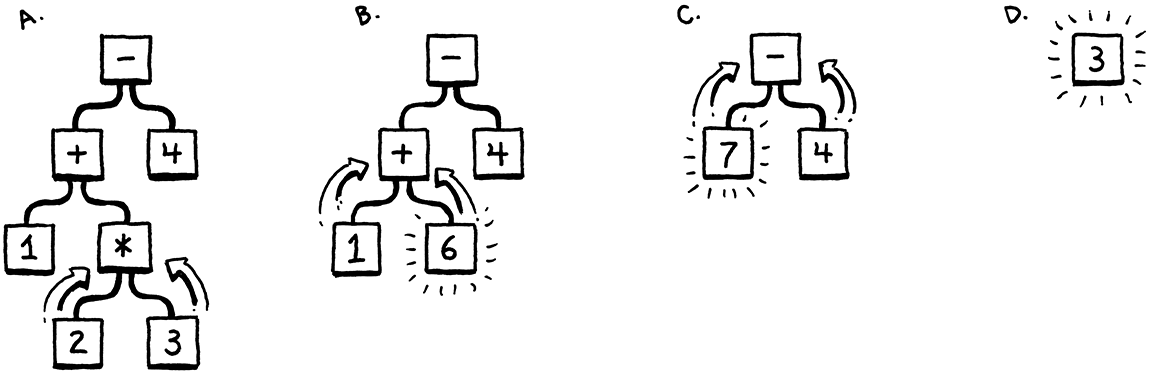
如果我给你一个算术表达式,你可以很容易地画出这样的树;给你一棵树,你也可以毫不费力地进行计算。因此,从直观上看,我们的代码的一种可行的表示形式是一棵与文法结构(运算符嵌套)相匹配的树。
那么我们需要更精确地了解这个文法是什么。就像上一章的词法文法一样,围绕句法文法也有一大堆理论。我们要比之前处理扫描时投入更多精力去研究这个理论,因为它在整个解释器的很多地方都是一个有用的工具。我们先从乔姆斯基谱系中往上升一级 . . .
5 . 1上下文无关文法
在上一章中,我们用来定义词法文法(字符如何被分组为词法标记的规则)的形式体系,被称为正则语言。这对于我们的扫描器来说没什么问题,因为它输出的是一个扁平的词法标记序列。但正则语言还不够强大,无法处理可以任意深度嵌套的表达式。
我们还需要一个更强大的工具,就是上下文无关文法(context-free grammar,CFG)。它是形式化文法的工具箱中又一个重量级的工具。一个形式化文法需要一组原子片段,它称之为“alphabet(字母表)”。然后它定义了一组(通常是无限的)“strings(字符串)”,这些字符串“包含”在文法中。每个字符串都是字母表中“letters(字符)”的序列。
我这里使用引号是因为当你从词法文法转到语法文法时,这些术语会让你有点困惑。在我们的扫描器词法中,alphabet(字母表)由单个字符组成,strings(字符串)是有效的词素(粗略的说,就是“单词”)。在现在讨论的语法文法中,我们处于一个不同的粒度水平。现在,字母表中的一个“letters(字符)”是一个完整的词法标记,而“strings(字符串)”是一个词法标记系列——一个完整的表达式。
嗯,使用表格可能更有助于理解:
| Terminology | Lexical grammar | Syntactic grammar | |
| The “alphabet” is . . . | → | Characters | Tokens |
| A “string” is . . . | → | Lexeme or token | Expression |
| It’s implemented by the . . . | → | Scanner | Parser |
形式化文法的工作是指定哪些字符串有效,哪些无效。如果我们要为英语句子定义一个文法,“eggs are tasty for breakfast”会包含在文法中,但“tasty breakfast for are eggs”可能不会。
5 . 1 . 1文法规则
我们如何写下一个包含无限多有效字符串的文法?我们显然无法一一列举出来。相反,我们创建了一组有限的规则。你可以把它们想象成一场你可以朝两个方向“玩”的游戏。
如果你从规则入手,你可以用它们生成文法中的字符串。以这种方式创建的字符串被称为推导式(派生式),因为每个字符串都是从文法规则中推导出来的。在游戏的每一步中,你都要选择一条规则,然后按照它告诉你的去做。围绕形式化文法的大部分语言都倾向这种方式。规则被称为产生式,因为它们产生了文法中的字符串。
上下文无关文法中的每个产生式都有一个头部(其名称)和描述其生成内容的主体。在纯粹的形式上看,主体只是一系列符号。符号有两种:
-
终结符是文法字母表中的一个字母。你可以把它想象成一个字面量值。在我们定义的文法中,终结符是独立的词素——来自扫描器的词法标记,比如
if或1234。这些词素被称为“终结符”,表示“终点”,因为它们不会导致游戏中任何进一步的“动作”。你只是简单地产生了那一个符号。
-
非终结符是对语法中另一条规则的命名引用。它的意思是“执行那条规则,然后将它产生的任何内容插入这里”。这样,文法就构造完成了。
还有最后一个细节:你可以有多个同名的规则。当你遇到一个该名字的非终结符时,你可以为它选择任何一条规则,随你喜欢。
To make this concrete, we need a way to write down these production rules. People have been trying to crystallize grammar all the way back to Pāṇini’s Ashtadhyayi, which codified Sanskrit grammar a mere couple thousand years ago. Not much progress happened until John Backus and company needed a notation for specifying ALGOL 58 and came up with Backus-Naur form (BNF). Since then, nearly everyone uses some flavor of BNF, tweaked to their own tastes.
I tried to come up with something clean. Each rule is a name, followed by an
arrow (→), followed by a sequence of symbols, and finally ending with a
semicolon (;). Terminals are quoted strings, and nonterminals are lowercase
words.
Using that, here’s a grammar for breakfast menus:
breakfast → protein "with" breakfast "on the side" ; breakfast → protein ; breakfast → bread ; protein → crispiness "crispy" "bacon" ; protein → "sausage" ; protein → cooked "eggs" ; crispiness → "really" ; crispiness → "really" crispiness ; cooked → "scrambled" ; cooked → "poached" ; cooked → "fried" ; bread → "toast" ; bread → "biscuits" ; bread → "English muffin" ;
We can use this grammar to generate random breakfasts. Let’s play a round and
see how it works. By age-old convention, the game starts with the first rule in
the grammar, here breakfast. There are three productions for that, and we
randomly pick the first one. Our resulting string looks like:
protein "with" breakfast "on the side"
We need to expand that first nonterminal, protein, so we pick a production for
that. Let’s pick:
protein → cooked "eggs" ;
Next, we need a production for cooked, and so we pick "poached". That’s a
terminal, so we add that. Now our string looks like:
"poached" "eggs" "with" breakfast "on the side"
The next non-terminal is breakfast again. The first breakfast production we
chose recursively refers back to the breakfast rule. Recursion in the grammar
is a good sign that the language being defined is context-free instead of
regular. In particular, recursion where the recursive nonterminal has
productions on both sides implies that the language is
not regular.
We could keep picking the first production for breakfast over and over again
yielding all manner of breakfasts like “bacon with sausage with scrambled eggs
with bacon . . . ” We won’t though. This time we’ll pick bread. There are three
rules for that, each of which contains only a terminal. We’ll pick “English
muffin”.
With that, every nonterminal in the string has been expanded until it finally contains only terminals and we’re left with:
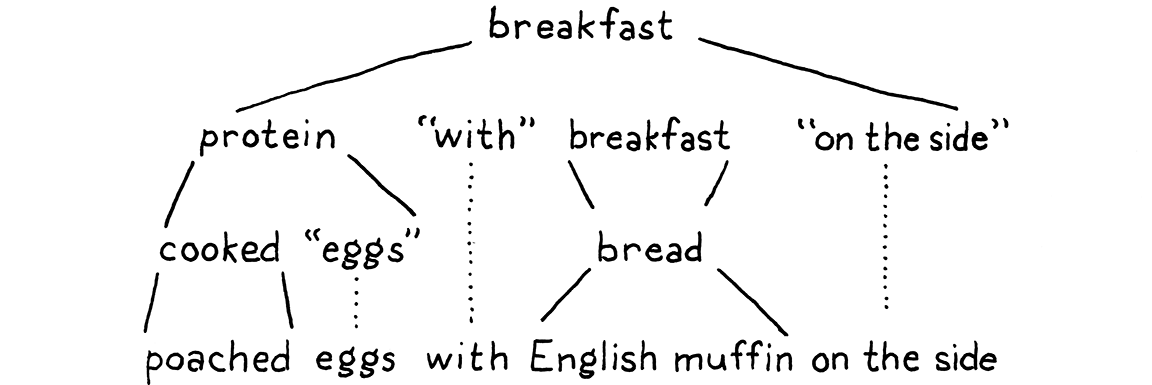
Throw in some ham and Hollandaise, and you’ve got eggs Benedict.
Any time we hit a rule that had multiple productions, we just picked one arbitrarily. It is this flexibility that allows a short number of grammar rules to encode a combinatorially larger set of strings. The fact that a rule can refer to itself—directly or indirectly—kicks it up even more, letting us pack an infinite number of strings into a finite grammar.
5 . 1 . 2Enhancing our notation
Stuffing an infinite set of strings in a handful of rules is pretty fantastic, but let’s take it further. Our notation works, but it’s tedious. So, like any good language designer, we’ll sprinkle a little syntactic sugar on top—some extra convenience notation. In addition to terminals and nonterminals, we’ll allow a few other kinds of expressions in the body of a rule:
-
Instead of repeating the rule name each time we want to add another production for it, we’ll allow a series of productions separated by a pipe (
|).bread → "toast" | "biscuits" | "English muffin" ;
-
Further, we’ll allow parentheses for grouping and then allow
|within that to select one from a series of options within the middle of a production.protein → ( "scrambled" | "poached" | "fried" ) "eggs" ;
-
Using recursion to support repeated sequences of symbols has a certain appealing purity, but it’s kind of a chore to make a separate named sub-rule each time we want to loop. So, we also use a postfix
*to allow the previous symbol or group to be repeated zero or more times.crispiness → "really" "really"* ;
-
A postfix
+is similar, but requires the preceding production to appear at least once.crispiness → "really"+ ;
-
A postfix
?is for an optional production. The thing before it can appear zero or one time, but not more.breakfast → protein ( "with" breakfast "on the side" )? ;
With all of those syntactic niceties, our breakfast grammar condenses down to:
breakfast → protein ( "with" breakfast "on the side" )? | bread ; protein → "really"+ "crispy" "bacon" | "sausage" | ( "scrambled" | "poached" | "fried" ) "eggs" ; bread → "toast" | "biscuits" | "English muffin" ;
Not too bad, I hope. If you’re used to grep or using regular expressions in your text editor, most of the punctuation should be familiar. The main difference is that symbols here represent entire tokens, not single characters.
We’ll use this notation throughout the rest of the book to precisely describe Lox’s grammar. As you work on programming languages, you’ll find that context-free grammars (using this or EBNF or some other notation) help you crystallize your informal syntax design ideas. They are also a handy medium for communicating with other language hackers about syntax.
The rules and productions we define for Lox are also our guide to the tree data structure we’re going to implement to represent code in memory. Before we can do that, we need an actual grammar for Lox, or at least enough of one for us to get started.
5 . 1 . 3A Grammar for Lox expressions
In the previous chapter, we did Lox’s entire lexical grammar in one fell swoop. Every keyword and bit of punctuation is there. The syntactic grammar is larger, and it would be a real bore to grind through the entire thing before we actually get our interpreter up and running.
Instead, we’ll crank through a subset of the language in the next couple of chapters. Once we have that mini-language represented, parsed, and interpreted, then later chapters will progressively add new features to it, including the new syntax. For now, we are going to worry about only a handful of expressions:
-
Literals. Numbers, strings, Booleans, and
nil. -
Unary expressions. A prefix
!to perform a logical not, and-to negate a number. -
Binary expressions. The infix arithmetic (
+,-,*,/) and logic operators (==,!=,<,<=,>,>=) we know and love. -
Parentheses. A pair of
(and)wrapped around an expression.
That gives us enough syntax for expressions like:
1 - (2 * 3) < 4 == false
Using our handy dandy new notation, here’s a grammar for those:
expression → literal | unary | binary | grouping ; literal → NUMBER | STRING | "true" | "false" | "nil" ; grouping → "(" expression ")" ; unary → ( "-" | "!" ) expression ; binary → expression operator expression ; operator → "==" | "!=" | "<" | "<=" | ">" | ">=" | "+" | "-" | "*" | "/" ;
There’s one bit of extra metasyntax here. In addition
to quoted strings for terminals that match exact lexemes, we CAPITALIZE
terminals that are a single lexeme whose text representation may vary. NUMBER
is any number literal, and STRING is any string literal. Later, we’ll do the
same for IDENTIFIER.
This grammar is actually ambiguous, which we’ll see when we get to parsing it. But it’s good enough for now.
5 . 2Implementing Syntax Trees
Finally, we get to write some code. That little expression grammar is our
skeleton. Since the grammar is recursive—note how grouping, unary, and
binary all refer back to expression—our data structure will form a tree.
Since this structure represents the syntax of our language, it’s called a syntax tree.
Our scanner used a single Token class to represent all kinds of lexemes. To
distinguish the different kinds—think the number 123 versus the string
"123"—we included a simple TokenType enum. Syntax trees are not so homogeneous. Unary expressions have a single operand,
binary expressions have two, and literals have none.
We could mush that all together into a single Expression class with an
arbitrary list of children. Some compilers do. But I like getting the most out
of Java’s type system. So we’ll define a base class for expressions. Then, for
each kind of expression—each production under expression—we create a
subclass that has fields for the nonterminals specific to that rule. This way,
we get a compile error if we, say, try to access the second operand of a unary
expression.
Something like this:
package com.craftinginterpreters.lox; abstract class Expr { static class Binary extends Expr { Binary(Expr left, Token operator, Expr right) { this.left = left; this.operator = operator; this.right = right; } final Expr left; final Token operator; final Expr right; } // Other expressions... }
Expr is the base class that all expression classes inherit from. As you can see
from Binary, the subclasses are nested inside of it. There’s no technical need
for this, but it lets us cram all of the classes into a single Java file.
5 . 2 . 1Disoriented objects
You’ll note that, much like the Token class, there aren’t any methods here. It’s a dumb structure. Nicely typed, but merely a bag of data. This feels strange in an object-oriented language like Java. Shouldn’t the class do stuff?
The problem is that these tree classes aren’t owned by any single domain. Should they have methods for parsing since that’s where the trees are created? Or interpreting since that’s where they are consumed? Trees span the border between those territories, which means they are really owned by neither.
In fact, these types exist to enable the parser and interpreter to communicate. That lends itself to types that are simply data with no associated behavior. This style is very natural in functional languages like Lisp and ML where all data is separate from behavior, but it feels odd in Java.
Functional programming aficionados right now are jumping up to exclaim “See! Object-oriented languages are a bad fit for an interpreter!” I won’t go that far. You’ll recall that the scanner itself was admirably suited to object-orientation. It had all of the mutable state to keep track of where it was in the source code, a well-defined set of public methods, and a handful of private helpers.
My feeling is that each phase or part of the interpreter works fine in an object-oriented style. It is the data structures that flow between them that are stripped of behavior.
5 . 2 . 2Metaprogramming the trees
Java can express behavior-less classes, but I wouldn’t say that it’s particularly great at it. Eleven lines of code to stuff three fields in an object is pretty tedious, and when we’re all done, we’re going to have 21 of these classes.
I don’t want to waste your time or my ink writing all that down. Really, what is the essence of each subclass? A name, and a list of typed fields. That’s it. We’re smart language hackers, right? Let’s automate.
Instead of tediously handwriting each class definition, field declaration, constructor, and initializer, we’ll hack together a script that does it for us. It has a description of each tree type—its name and fields—and it prints out the Java code needed to define a class with that name and state.
This script is a tiny Java command-line app that generates a file named “Expr.java”:
create new file
package com.craftinginterpreters.tool; import java.io.IOException; import java.io.PrintWriter; import java.util.Arrays; import java.util.List; public class GenerateAst { public static void main(String[] args) throws IOException { if (args.length != 1) { System.err.println("Usage: generate_ast <output directory>"); System.exit(64); } String outputDir = args[0]; } }
Note that this file is in a different package, .tool instead of .lox. This
script isn’t part of the interpreter itself. It’s a tool we, the people
hacking on the interpreter, run ourselves to generate the syntax tree classes.
When it’s done, we treat “Expr.java” like any other file in the implementation.
We are merely automating how that file gets authored.
To generate the classes, it needs to have some description of each type and its fields.
String outputDir = args[0];
in main()
defineAst(outputDir, "Expr", Arrays.asList( "Binary : Expr left, Token operator, Expr right", "Grouping : Expr expression", "Literal : Object value", "Unary : Token operator, Expr right" ));
}
For brevity’s sake, I jammed the descriptions of the expression types into
strings. Each is the name of the class followed by : and the list of fields,
separated by commas. Each field has a type and a name.
The first thing defineAst() needs to do is output the base Expr class.
add after main()
private static void defineAst( String outputDir, String baseName, List<String> types) throws IOException { String path = outputDir + "/" + baseName + ".java"; PrintWriter writer = new PrintWriter(path, "UTF-8"); writer.println("package com.craftinginterpreters.lox;"); writer.println(); writer.println("import java.util.List;"); writer.println(); writer.println("abstract class " + baseName + " {"); writer.println("}"); writer.close(); }
When we call this, baseName is “Expr”, which is both the name of the class and
the name of the file it outputs. We pass this as an argument instead of
hardcoding the name because we’ll add a separate family of classes later for
statements.
Inside the base class, we define each subclass.
writer.println("abstract class " + baseName + " {");
in defineAst()
// The AST classes. for (String type : types) { String className = type.split(":")[0].trim(); String fields = type.split(":")[1].trim(); defineType(writer, baseName, className, fields); }
writer.println("}");
That code, in turn, calls:
add after defineAst()
private static void defineType( PrintWriter writer, String baseName, String className, String fieldList) { writer.println(" static class " + className + " extends " + baseName + " {"); // Constructor. writer.println(" " + className + "(" + fieldList + ") {"); // Store parameters in fields. String[] fields = fieldList.split(", "); for (String field : fields) { String name = field.split(" ")[1]; writer.println(" this." + name + " = " + name + ";"); } writer.println(" }"); // Fields. writer.println(); for (String field : fields) { writer.println(" final " + field + ";"); } writer.println(" }"); }
There we go. All of that glorious Java boilerplate is done. It declares each field in the class body. It defines a constructor for the class with parameters for each field and initializes them in the body.
Compile and run this Java program now and it blasts out a new “.java” file containing a few dozen lines of code. That file’s about to get even longer.
5 . 3Working with Trees
Put on your imagination hat for a moment. Even though we aren’t there yet, consider what the interpreter will do with the syntax trees. Each kind of expression in Lox behaves differently at runtime. That means the interpreter needs to select a different chunk of code to handle each expression type. With tokens, we can simply switch on the TokenType. But we don’t have a “type” enum for the syntax trees, just a separate Java class for each one.
We could write a long chain of type tests:
if (expr instanceof Expr.Binary) { // ... } else if (expr instanceof Expr.Grouping) { // ... } else // ...
But all of those sequential type tests are slow. Expression types whose names
are alphabetically later would take longer to execute because they’d fall
through more if cases before finding the right type. That’s not my idea of an
elegant solution.
We have a family of classes and we need to associate a chunk of behavior with
each one. The natural solution in an object-oriented language like Java is to
put those behaviors into methods on the classes themselves. We could add an
abstract interpret() method on Expr
which each subclass would then implement to interpret itself.
This works alright for tiny projects, but it scales poorly. Like I noted before, these tree classes span a few domains. At the very least, both the parser and interpreter will mess with them. As you’ll see later, we need to do name resolution on them. If our language was statically typed, we’d have a type checking pass.
If we added instance methods to the expression classes for every one of those operations, that would smush a bunch of different domains together. That violates separation of concerns and leads to hard-to-maintain code.
5 . 3 . 1The expression problem
This problem is more fundamental than it may seem at first. We have a handful of types, and a handful of high-level operations like “interpret”. For each pair of type and operation, we need a specific implementation. Picture a table:
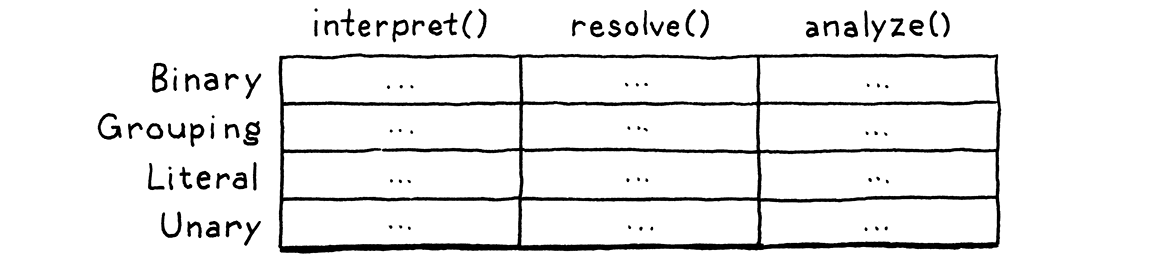
Rows are types, and columns are operations. Each cell represents the unique piece of code to implement that operation on that type.
An object-oriented language like Java assumes that all of the code in one row naturally hangs together. It figures all the things you do with a type are likely related to each other, and the language makes it easy to define them together as methods inside the same class.
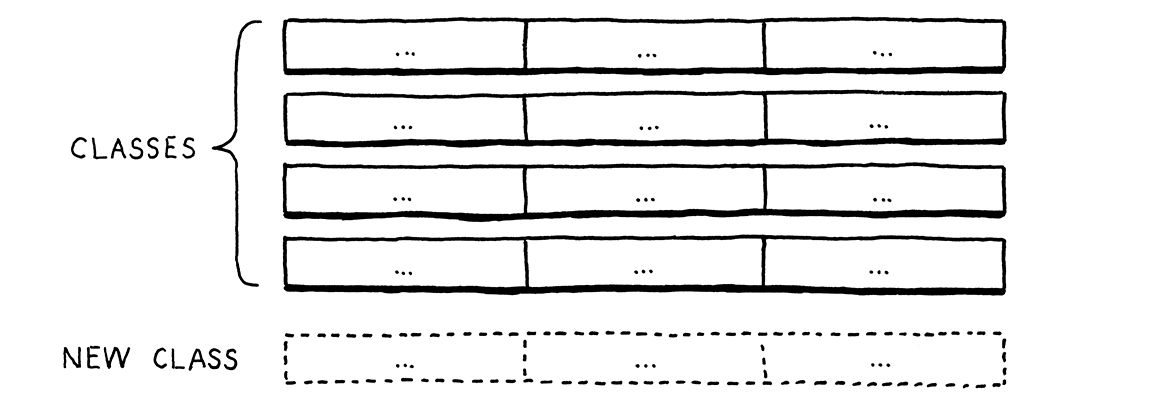
This makes it easy to extend the table by adding new rows. Simply define a new class. No existing code has to be touched. But imagine if you want to add a new operation—a new column. In Java, that means cracking open each of those existing classes and adding a method to it.
Functional paradigm languages in the ML family flip that around. There, you don’t have classes with methods. Types and functions are totally distinct. To implement an operation for a number of different types, you define a single function. In the body of that function, you use pattern matching—sort of a type-based switch on steroids—to implement the operation for each type all in one place.
This makes it trivial to add new operations—simply define another function that pattern matches on all of the types.
But, conversely, adding a new type is hard. You have to go back and add a new case to all of the pattern matches in all of the existing functions.
Each style has a certain “grain” to it. That’s what the paradigm name literally says—an object-oriented language wants you to orient your code along the rows of types. A functional language instead encourages you to lump each column’s worth of code together into a function.
A bunch of smart language nerds noticed that neither style made it easy to add both rows and columns to the table. They called this difficulty the “expression problem” because—like we are now—they first ran into it when they were trying to figure out the best way to model expression syntax tree nodes in a compiler.
People have thrown all sorts of language features, design patterns, and programming tricks to try to knock that problem down but no perfect language has finished it off yet. In the meantime, the best we can do is try to pick a language whose orientation matches the natural architectural seams in the program we’re writing.
Object-orientation works fine for many parts of our interpreter, but these tree classes rub against the grain of Java. Fortunately, there’s a design pattern we can bring to bear on it.
5 . 3 . 2The Visitor pattern
The Visitor pattern is the most widely misunderstood pattern in all of Design Patterns, which is really saying something when you look at the software architecture excesses of the past couple of decades.
The trouble starts with terminology. The pattern isn’t about “visiting”, and the “accept” method in it doesn’t conjure up any helpful imagery either. Many think the pattern has to do with traversing trees, which isn’t the case at all. We are going to use it on a set of classes that are tree-like, but that’s a coincidence. As you’ll see, the pattern works as well on a single object.
The Visitor pattern is really about approximating the functional style within an OOP language. It lets us add new columns to that table easily. We can define all of the behavior for a new operation on a set of types in one place, without having to touch the types themselves. It does this the same way we solve almost every problem in computer science: by adding a layer of indirection.
Before we apply it to our auto-generated Expr classes, let’s walk through a simpler example. Say we have two kinds of pastries: beignets and crullers.
abstract class Pastry { } class Beignet extends Pastry { } class Cruller extends Pastry { }
We want to be able to define new pastry operations—cooking them, eating them, decorating them, etc.—without having to add a new method to each class every time. Here’s how we do it. First, we define a separate interface.
interface PastryVisitor { void visitBeignet(Beignet beignet); void visitCruller(Cruller cruller); }
Each operation that can be performed on pastries is a new class that implements that interface. It has a concrete method for each type of pastry. That keeps the code for the operation on both types all nestled snugly together in one class.
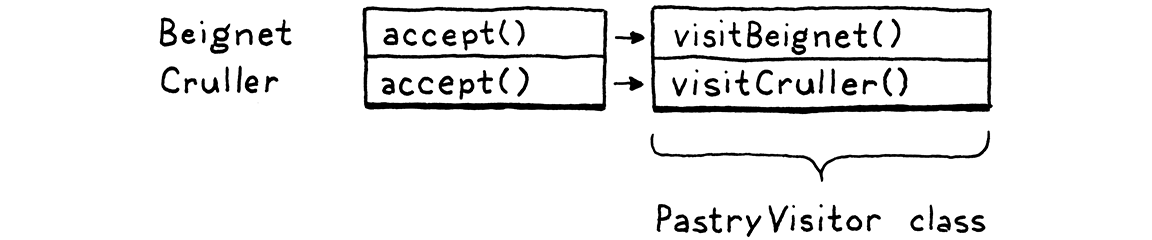
Given some pastry, how do we route it to the correct method on the visitor based on its type? Polymorphism to the rescue! We add this method to Pastry:
abstract class Pastry {
abstract void accept(PastryVisitor visitor);
}
Each subclass implements it.
class Beignet extends Pastry {
@Override void accept(PastryVisitor visitor) { visitor.visitBeignet(this); }
}
And:
class Cruller extends Pastry {
@Override void accept(PastryVisitor visitor) { visitor.visitCruller(this); }
}
To perform an operation on a pastry, we call its accept() method and pass in
the visitor for the operation we want to execute. The pastry—the specific
subclass’s overriding implementation of accept()—turns around and calls the
appropriate visit method on the visitor and passes itself to it.
That’s the heart of the trick right there. It lets us use polymorphic dispatch on the pastry classes to select the appropriate method on the visitor class. In the table, each pastry class is a row, but if you look at all of the methods for a single visitor, they form a column.
We added one accept() method to each class, and we can use it for as many
visitors as we want without ever having to touch the pastry classes again. It’s
a clever pattern.
5 . 3 . 3Visitors for expressions
OK, let’s weave it into our expression classes. We’ll also refine the pattern a little. In the pastry example, the
visit and accept() methods don’t return anything. In practice, visitors often
want to define operations that produce values. But what return type should
accept() have? We can’t assume every visitor class wants to produce the same
type, so we’ll use generics to let each implementation fill in a return type.
First, we define the visitor interface. Again, we nest it inside the base class so that we can keep everything in one file.
writer.println("abstract class " + baseName + " {");
in defineAst()
defineVisitor(writer, baseName, types);
// The AST classes.
That function generates the visitor interface.
add after defineAst()
private static void defineVisitor( PrintWriter writer, String baseName, List<String> types) { writer.println(" interface Visitor<R> {"); for (String type : types) { String typeName = type.split(":")[0].trim(); writer.println(" R visit" + typeName + baseName + "(" + typeName + " " + baseName.toLowerCase() + ");"); } writer.println(" }"); }
Here, we iterate through all of the subclasses and declare a visit method for each one. When we define new expression types later, this will automatically include them.
Inside the base class, we define the abstract accept() method.
defineType(writer, baseName, className, fields);
}
in defineAst()
// The base accept() method.
writer.println();
writer.println(" abstract <R> R accept(Visitor<R> visitor);");
writer.println("}");
Finally, each subclass implements that and calls the right visit method for its own type.
writer.println(" }");
in defineType()
// Visitor pattern.
writer.println();
writer.println(" @Override");
writer.println(" <R> R accept(Visitor<R> visitor) {");
writer.println(" return visitor.visit" +
className + baseName + "(this);");
writer.println(" }");
// Fields.
There we go. Now we can define operations on expressions without having to muck with the classes or our generator script. Compile and run this generator script to output an updated “Expr.java” file. It contains a generated Visitor interface and a set of expression node classes that support the Visitor pattern using it.
Before we end this rambling chapter, let’s implement that Visitor interface and see the pattern in action.
5 . 4A (Not Very) Pretty Printer
When we debug our parser and interpreter, it’s often useful to look at a parsed syntax tree and make sure it has the structure we expect. We could inspect it in the debugger, but that can be a chore.
Instead, we’d like some code that, given a syntax tree, produces an unambiguous string representation of it. Converting a tree to a string is sort of the opposite of a parser, and is often called “pretty printing” when the goal is to produce a string of text that is valid syntax in the source language.
That’s not our goal here. We want the string to very explicitly show the nesting
structure of the tree. A printer that returned 1 + 2 * 3 isn’t super helpful
if what we’re trying to debug is whether operator precedence is handled
correctly. We want to know if the + or * is at the top of the tree.
To that end, the string representation we produce isn’t going to be Lox syntax. Instead, it will look a lot like, well, Lisp. Each expression is explicitly parenthesized, and all of its subexpressions and tokens are contained in that.
Given a syntax tree like:
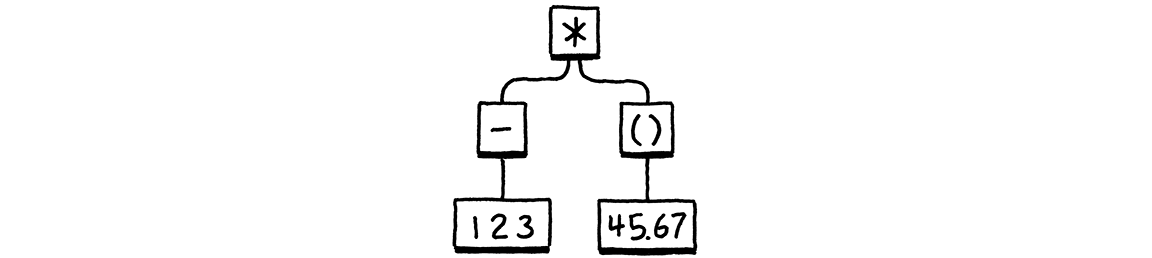
It produces:
(* (- 123) (group 45.67))
Not exactly “pretty”, but it does show the nesting and grouping explicitly. To implement this, we define a new class.
create new file
package com.craftinginterpreters.lox; class AstPrinter implements Expr.Visitor<String> { String print(Expr expr) { return expr.accept(this); } }
As you can see, it implements the visitor interface. That means we need visit methods for each of the expression types we have so far.
return expr.accept(this); }
add after print()
@Override public String visitBinaryExpr(Expr.Binary expr) { return parenthesize(expr.operator.lexeme, expr.left, expr.right); } @Override public String visitGroupingExpr(Expr.Grouping expr) { return parenthesize("group", expr.expression); } @Override public String visitLiteralExpr(Expr.Literal expr) { if (expr.value == null) return "nil"; return expr.value.toString(); } @Override public String visitUnaryExpr(Expr.Unary expr) { return parenthesize(expr.operator.lexeme, expr.right); }
}
Literal expressions are easy—they convert the value to a string with a little
check to handle Java’s null standing in for Lox’s nil. The other expressions
have subexpressions, so they use this parenthesize() helper method:
add after visitUnaryExpr()
private String parenthesize(String name, Expr... exprs) { StringBuilder builder = new StringBuilder(); builder.append("(").append(name); for (Expr expr : exprs) { builder.append(" "); builder.append(expr.accept(this)); } builder.append(")"); return builder.toString(); }
It takes a name and a list of subexpressions and wraps them all up in parentheses, yielding a string like:
(+ 1 2)
Note that it calls accept() on each subexpression and passes in itself. This
is the recursive step that lets us print an entire
tree.
We don’t have a parser yet, so it’s hard to see this in action. For now, we’ll
hack together a little main() method that manually instantiates a tree and
prints it.
add after parenthesize()
public static void main(String[] args) { Expr expression = new Expr.Binary( new Expr.Unary( new Token(TokenType.MINUS, "-", null, 1), new Expr.Literal(123)), new Token(TokenType.STAR, "*", null, 1), new Expr.Grouping( new Expr.Literal(45.67))); System.out.println(new AstPrinter().print(expression)); }
If we did everything right, it prints:
(* (- 123) (group 45.67))
You can go ahead and delete this method. We won’t need it. Also, as we add new syntax tree types, I won’t bother showing the necessary visit methods for them in AstPrinter. If you want to (and you want the Java compiler to not yell at you), go ahead and add them yourself. It will come in handy in the next chapter when we start parsing Lox code into syntax trees. Or, if you don’t care to maintain AstPrinter, feel free to delete it. We won’t need it again.
Challenges
-
Earlier, I said that the
|,*, and+forms we added to our grammar metasyntax were just syntactic sugar. Take this grammar:expr → expr ( "(" ( expr ( "," expr )* )? ")" | "." IDENTIFIER )+ | IDENTIFIER | NUMBER
Produce a grammar that matches the same language but does not use any of that notational sugar.
Bonus: What kind of expression does this bit of grammar encode?
-
The Visitor pattern lets you emulate the functional style in an object-oriented language. Devise a complementary pattern for a functional language. It should let you bundle all of the operations on one type together and let you define new types easily.
(SML or Haskell would be ideal for this exercise, but Scheme or another Lisp works as well.)
-
In reverse Polish notation (RPN), the operands to an arithmetic operator are both placed before the operator, so
1 + 2becomes1 2 +. Evaluation proceeds from left to right. Numbers are pushed onto an implicit stack. An arithmetic operator pops the top two numbers, performs the operation, and pushes the result. Thus, this:(1 + 2) * (4 - 3)
in RPN becomes:
1 2 + 4 3 - *
Define a visitor class for our syntax tree classes that takes an expression, converts it to RPN, and returns the resulting string.