分析处理
大量数据存储在公司的各种事务数据库系统中,它们可以为公司业务运营提供宝贵的参考意见。例如,分析订单处理系统的数据,可以获得销量随时间的增长曲线;可以识别延迟发货的原因;还可以预测未来的销量以便提前调整库存。但是,事务数据通常分布在多个数据库中,它们往往汇总起来联合分析时更有价值。而且,数据通常需要转换为通用格式。
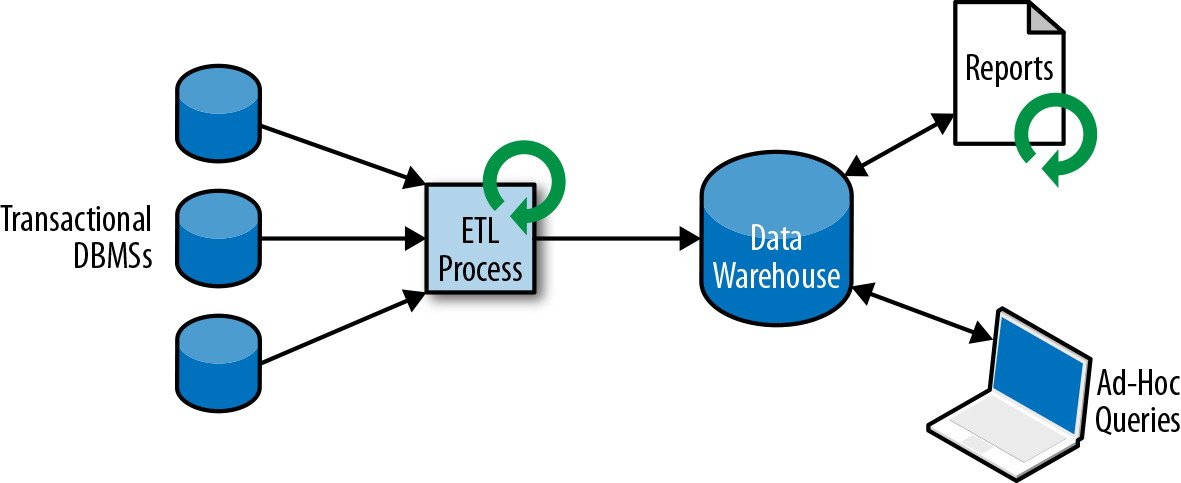
所以我们一般不会直接在事务数据库上运行分析查询,而是复制数据到数据仓库。数据仓库是对工作负载进行分析和查询的专用数据存储。为了填充数据仓库,需要将事务数据库系统管理的数据复制过来。将数据复制到数据仓库的过程称为extract-transform-load(ETL)。 ETL过程从事务数据库中提取数据,将其转换为某种通用的结构表示,可能包括验证,值的规范化,编码,重复数据删除(去重)和模式转换,最后将其加载到分析数据库中。 ETL过程可能非常复杂,并且通常需要技术复杂的解决方案来满足性能要求。 ETL过程需要定期运行以保持数据仓库中的数据同步。
将数据导入数据仓库后,可以查询和分析数据。通常,在数据仓库上执行两类查询。第一种类型是定期报告查询,用于计算与业务相关的统计信息,比如收入、用户增长或者输出的产量。这些指标汇总到报告中,帮助管理层评估业务的整体健康状况。第二种类型是即席查询,旨在提供特定问题的答案并支持关键业务决策,例如收集统计在投放商业广告上的花费,和获取的相应收入,以评估营销活动的有效性。两种查询由批处理方式由数据仓库执行,如图1-3所示。
如今,Apache Hadoop生态系统的组件,已经是许多企业IT基础架构中不可或缺的组成部分。现在的做法不是直接将所有数据都插入关系数据库系统,而是将大量数据(如日志文件,社交媒体或Web点击日志)写入Hadoop的分布式文件系统(HDFS)、S3或其他批量数据存储库,如Apache HBase,以较低的成本提供大容量存储容量。驻留在此类存储系统中的数据可以通过SQL-on-Hadoop引擎查询和处理,例如Apache Hive,Apache Drill或Apache Impala。但是,基础结构与传统数据仓库架构基本相同。