有状态的流式处理
日常生活中,所有数据都是作为连续的事件流创建的。比如网站或者移动应用中的用户交互动作,订单的提交,服务器日志或传感器测量数据:所有这些都是事件流。实际上,很少有应用场景,能一次性地生成所需要的完整(有限)数据集。实际应用中更多的是无限事件流。有状态的流处理就是用于处理这种无限事件流的应用程序设计模式,在公司的IT基础设施中有广泛的应用场景。在我们讨论其用例之前,我们将简要介绍有状态流处理的工作原理。
如果我们想要无限处理事件流,并且不愿意繁琐地每收到一个事件就记录一次,那这样的应用程序就需要是有状态的,也就是说能够存储和访问中间数据。当应用程序收到一个新事件时,它可以从状态中读取数据,或者向该状态写入数据,总之可以执行任何计算。原则上讲,我们可以在各种不同的地方存储和访问状态,包括程序变量(内存)、本地文件,还有嵌入式或外部数据库。
Apache Flink将应用程序状态,存储在内存或者嵌入式数据库中。由于Flink是一个分布式系统,因此需要保护本地状态以防止在应用程序或计算机故障时数据丢失。 Flink通过定期将应用程序状态的一致性检查点(check point)写入远程且持久的存储,来保证这一点。状态、状态一致性和Flink的检查点将在后面的章节中更详细地讨论,但是,现在,图1-4显示了有状态的流式Flink应用程序。
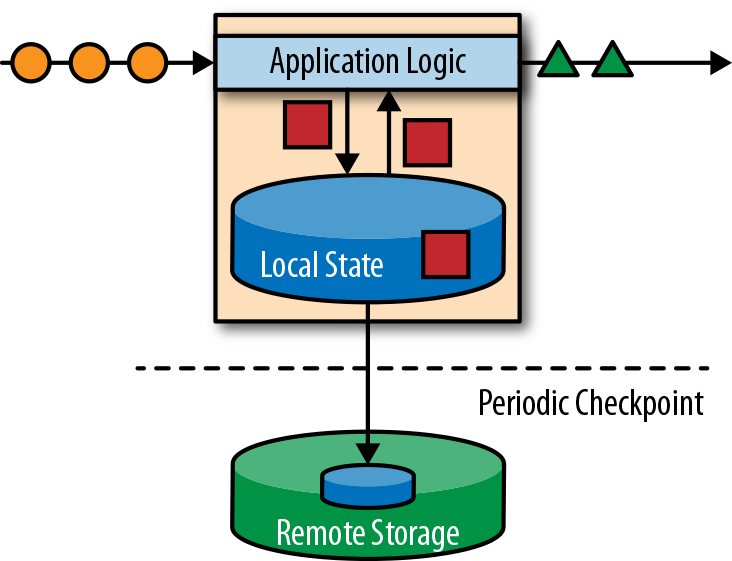
有状态的流处理应用程序,通常从事件日志中提取输入事件。事件日志就用来存储和分发事件流。事件被写入持久的仅添加(append-only)日志,这意味着无法更改写入事件的顺序。写入事件日志的流,可以被相同或不同的消费者多次读取。由于日志的仅附加(append-only)属性,事件始终以完全相同的顺序发布给所有消费者。现在已有几种事件日志系统,其中Apache Kafka是最受欢迎的,可以作为开源软件使用,或者是云计算提供商提供的集成服务。
在Flink上运行的有状态的流处理应用程序,是很有意思的一件事。在这个架构中,事件日志会按顺序保留输入事件,并且可以按确定的顺序重播它们。如果发生故障,Flink将从先前的检查点(check point)恢复其状态,并重置事件日志上的读取位置,这样就可以恢复整个应用。应用程序将重放(并快进)事件日志中的输入事件,直到它到达流的尾部。此技术一般用于从故障中恢复,但也可用于更新应用程序、修复bug或者修复以前发出的结果,另外还可以用于将应用程序迁移到其他群集,或使用不同的应用程序版本执行A / B测试。
如前所述,有状态的流处理是一种通用且灵活的设计架构,可用于许多不同的场景。在下文中,我们提出了三类通常使用有状态流处理实现的应用程序:(1)事件驱动应用程序,(2)数据管道应用程序,以及(3)数据分析应用程序。
我们将应用程序分类描述,是为了强调有状态流处理适用于多种业务场景;而实际的应用中,往往会具有以上多种情况的特征。