状态管理
在第2章中,我们已经知道大多数流应用程序都是有状态的。许多算子会不断地读取和更新状态,例如在窗口中收集的数据、读取输入源的位置,或者像机器学习模型那样的用户定制化的算子状态。 Flink用同样的方式处理所有的状态,无论是内置的还是用户自定义的算子。本节我们将会讨论Flink支持的不同类型的状态,并解释“状态后端”是如何存储和维护状态的。
一般来说,由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状态。你可以认为状态就是一个本地变量,可以被任务的业务逻辑访问。图3-10显示了任务与其状态之间的交互。
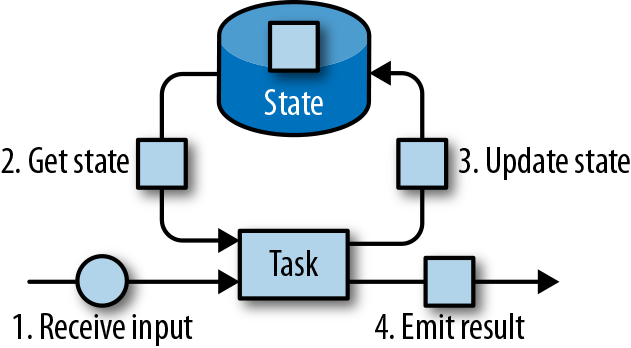
任务会接收一些输入数据。在处理数据时,任务可以读取和更新状态,并根据输入数据和状态计算结果。最简单的例子,就是统计接收到多少条数据的任务。当任务收到新数据时,它会访问状态以获取当前的计数,然后让计数递增,更新状态并发送出新的计数。
应用程序里,读取和写入状态的逻辑一般都很简单直接,而有效可靠的状态管理会复杂一些。这包括如何处理很大的状态——可能会超过内存,并且保证在发生故障时不会丢失任何状态。幸运的是,Flink会帮我们处理这相关的所有问题,包括状态一致性、故障处理以及高效存储和访问,以便开发人员可以专注于应用程序的逻辑。
在Flink中,状态始终与特定算子相关联。为了使运行时的Flink了解算子的状态,算子需要预先注册其状态。总的说来,有两种类型的状态:算子状态(operator state)和键控状态(keyed state),它们有着不同的范围访问,我们将在下面展开讨论。