Apache Kafka Source连接器
Apache Kafka是一个分布式流式平台。它的核心是一个分布式的发布订阅消息系统。
Kafka将事件流组织为所谓的topics。一个主题就是一个事件日志系统,Kafka可以保证主题中的数据在被读取时和这些数据在被写入时相同的顺序。为了扩大读写的规模,主题可以分裂为多个分区,这些分区分布在一个集群上面。这时,读写顺序的保证就限制到了分区这个粒度, Kafka并没有提供从不同分区读取数据时的顺序保证。Kafka分区的读位置称为偏移量(offset)。
Kafka的依赖引入如下:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.7.1</version>
</dependency>
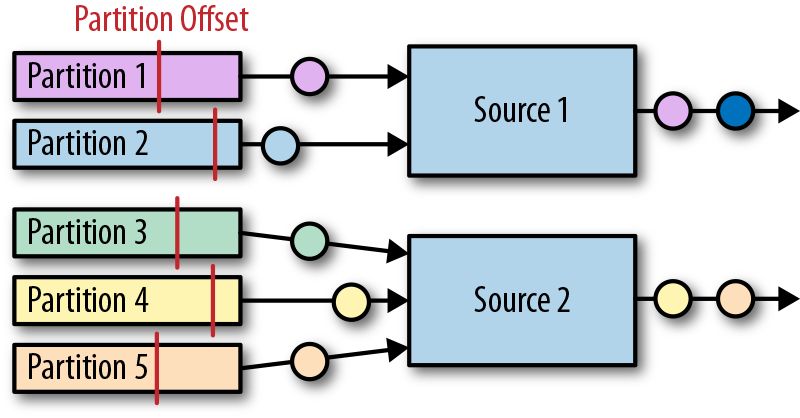
Flink Kafka连接器并行的摄入事件流。每一个并行source任务可以从一个或者多个分区中读取数据。任务将会跟踪每一个分区当前的读偏移量,然后将读偏移量写入到检查点数据中。当从任务故障恢复时,读偏移量将被恢复,而source任务将从检查点保存的读偏移量开始重新读取数据。Flink Kafka连接器并不依赖Kafka自己的offset-tracking机制(基于消费者组实现)。下图展示了分区如何分配给source实例。
Kafka source连接器使用如下代码创建
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "test")
val stream: DataStream[String] = env.addSource(
new FlinkKafkaConsumer[String](
"topic",
new SimpleStringSchema(),
properties))
构造器接受三个参数。第一个参数定义了从哪些topic中读取数据,可以是一个topic,也可以是topic列表,还可以是匹配所有想要读取的topic的正则表达式。当从多个topic中读取数据时,Kafka连接器将会处理所有topic的分区,将这些分区的数据放到一条流中去。
第二个参数是一个DeserializationSchema或者KeyedDeserializationSchema。Kafka消息被存储为原始的字节数据,所以需要反序列化成Java或者Scala对象。上例中使用的SimpleStringSchema,是一个内置的DeserializationSchema,它仅仅是简单的将字节数组反序列化成字符串。DeserializationSchema和KeyedDeserializationSchema是公共的接口,所以我们可以自定义反序列化逻辑。
第三个参数是一个Properties对象,设置了用来读写的Kafka客户端的一些属性。
为了抽取事件时间的时间戳然后产生水印,我们可以通过调用
FlinkKafkaConsumer.assignTimestampsAndWatermark()
方法为Kafka消费者提供AssignerWithPeriodicWatermark或者AssignerWithPucntuatedWatermark。每一个assigner都将被应用到每个分区,来利用每一个分区的顺序保证特性。source实例将会根据水印的传播协议聚合所有分区的水印。