高可用配置
流式应用程序一般被设计为7 x 24小时运行。所以很重要的一点是:即使出现了进程挂掉的情况,应用仍需要继续保持运行。为了从故障恢复,系统首先需要重启进程、然后重启应用并恢复它的状态。接下来,我们就来了解Flink如何重启失败的进程。
TaskManager故障
如前所述,Flink需要足够数目的slot,来执行一个应用的所有任务。假设一个Flink环境有4个TaskManager,每个提供2个插槽,那么流应用程序执行的最高并行度为8。如果其中一个TaskManager挂掉了,那么可用的slots会降到6。在这种情况下,作业管理器会请求ResourceManager提供更多的slots。如果此请求无法满足——例如应用跑在一个独立集群——那么作业管理器在有足够的slots之前,无法重启应用。应用的重启策略决定了作业管理器的重启频率,以及两次重启尝试之间的时间间隔。
作业管理器故障
比TaskManager故障更严重的问题是作业管理器故障。作业管理器控制整个流应用程序的执行,并维护执行中的元数据——例如指向已完成检查点的指针。若是对应的作业管理器挂掉,则流程序无法继续运行。所以这就导致在Flink应用中,作业管理器是单点故障。为了解决这个问题,Flink提供了高可用模式。在原先的作业管理器挂掉后,可以将一个作业的状态和元数据迁移到另一个作业管理器,并继续执行。
Flink的高可用模式基于Apache ZooKeeper,我们知道,ZooKeeper是用来管理需要协调和共识的分布式服务的系统。Flink主要利用ZooKeeper来进行领导者(leader)的选举,并把它作为一个高可用和持久化的数据存储。当在高可用模式下运行时,作业管理器会将JobGraph以及所有需要的元数据(例如应用程序的jar文件),写入到一个远程的持久化存储系统中。而且,作业管理器会将指向存储位置的指针,写入到ZooKeeper的数据存储中。在执行一个应用的过程中,作业管理器会接收每个独立任务检查点的状态句柄(也就是存储位置)。当一个检查点完成时(所有任务已经成功地将它们的状态写入到远程存储), 作业管理器把状态句柄写入远程存储,并将指向这个远程存储的指针写入ZooKeeper。这样,一个作业管理器挂掉之后再恢复,所需要的所有数据信息已经都保存在了远程存储,而ZooKeeper里存有指向此存储位置的指针。图3-3描述了这个设计:
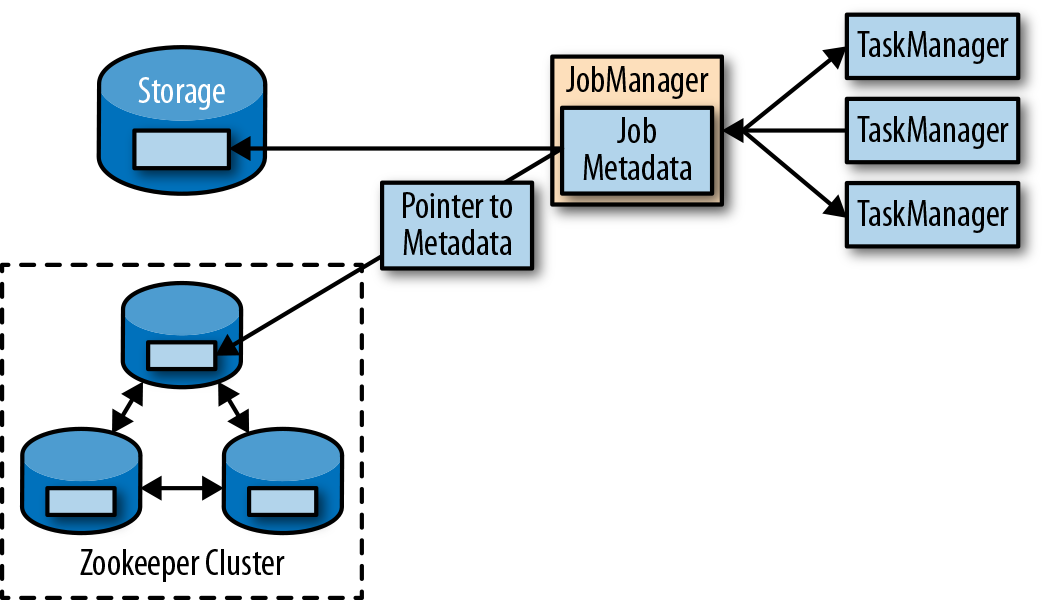
当一个作业管理器失败,所有属于这个应用的任务都会自动取消。一个新的作业管理器接管工作,会执行以下操作:
- 从ZooKeeper请求存储位置(storage location),从远端存储获取JobGraph,Jar文件,以及应用最近一次检查点(checkpoint)的状态句柄(state handles)
- 从ResourceManager请求slots,用来继续运行应用
- 重启应用,并将所有任务的状态,重设为最近一次已完成的检查点
如果我们是在容器环境里运行应用(如Kubernetes),故障的作业管理器或TaskManager 容器通常会由容器服务自动重启。当运行在YARN或Mesos之上时,作业管理器或TaskManager进程会由Flink的保留进程自动触发重启。而在standalone模式下,Flink并未提供重启故障进程的工具。所以,此模式下我们可以增加备用(standby)的 作业管理器和TaskManager,用于接管故障的进程。我们将会在“高可用配置”一节中做进一步讨论。